 At the time of writing this post I must say that I feel like a hero! That feeling is wonderful you know, when someone has a problem with their computer and not a simple but a HUGE one and you are able to repair em you turn to be that people hero.
At the time of writing this post I must say that I feel like a hero! That feeling is wonderful you know, when someone has a problem with their computer and not a simple but a HUGE one and you are able to repair em you turn to be that people hero.
Today my friend Avaco12 made a little mistake while installing bootcamp on her iMac, she left her external (200GB) disk connected, and when Windows asked her where to put the new Partition she accidentally selected her preciousus external drive, when she realized it was already too late, windows had already destroyed the partition table on her disk. She had 1 HFS parition and 1 FAT. She was crying because she said she had her entire life on that disk, so she asked me for help and I started researching what could I possibly do to repair the disk or at least retrieve her data.
 There are plenty of solutions out there, some of them are really expensive, and people on the forums are not very happy with them so I wanted to look at little more into the issue and I came across this solution called TestDisk which is an Open-Source Multi-platform solution for repairing disk partitions. I gave it a try and awesomely I managed to fix the disk using TestDisk and the pdisk utility.
There are plenty of solutions out there, some of them are really expensive, and people on the forums are not very happy with them so I wanted to look at little more into the issue and I came across this solution called TestDisk which is an Open-Source Multi-platform solution for repairing disk partitions. I gave it a try and awesomely I managed to fix the disk using TestDisk and the pdisk utility.
When I called Avaco12 to tell her that I fixed her data she was so happy she couldn’t stop smiling she told me I was her Hero and so that’s how I felt, the process wasn’t easy specially because noone talks about how pdisk works on Mac OS X.
Here’s how I did it , hope it works for you.
1.- I downloaded TestDisk from their official site :http://www.cgsecurity.org/wiki/TestDisk
2.- I opened the terminal and surfed to where I downloaded and unziped TestDisk
3.- I issued the command ‘sudo ./testdisk’ it indetially promped me to make my terminal bigger =P, after doing so It displayed me a simple disclaimer and then a notice telling me that TestDisk could Log all the activity if I wanted to. I selected Yes and continued.
4.- On the screen it will display you all the Disk it detects connected to your Mac select the one that got damaged partition tables and press Enter. Take note of which drive you selected, in my case I chosed /dev/rdisk1 (rather than /dev/disk1)
5.- Next screen select the menu Analize, it will probbly display you and error telling you the block 0 couldn’t be read, just hit enter on the ‘Quick Analize’ option
6.- ATTENTION: TestDisk will quickly search for partitions on the disk and display you information about it on your disk. Take note of the information it will display you, since you’ll need it to repair the disk later on with pdisk.
Here’s a screenshot of what I got:
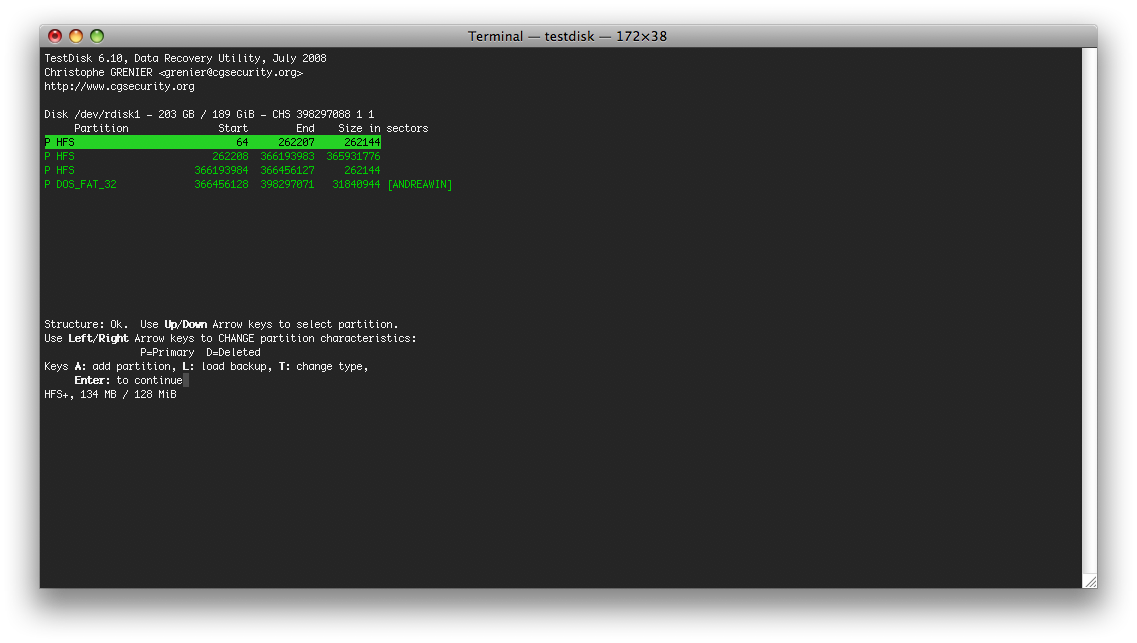
Note: if you try to repair your partition table with TestDisk it will fail since that function is not yet implemented.
7.- you can now exit TestDisk. The next steps are what distinguish a child from a Men
8.- Issue the command ‘sudo pdisk /dev/rdisk1’ (where /dev/rdisk1 should be the same name you chosed on step 4). If you type the command ‘c’ and hit enter it will tell you the following:
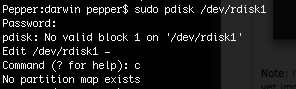
9.- That’s completely normal. Now type ‘i’ and it will display you some affirmations about block sizes and such, just hit enter:
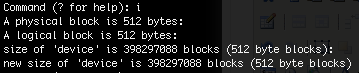
10.- Now we are going to need the info from Step 6. type the command ‘c’ and press enter, it will ask you to type down where your first partition starts, how long it is and how you want to name it. repeat this step for every partition you have.
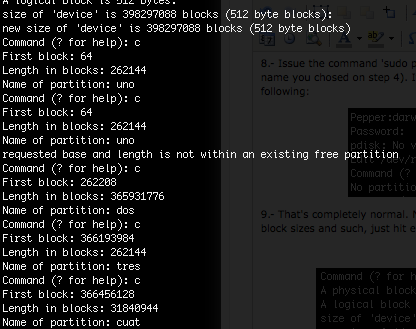
11. Now if you are completely sure you wrote down everything correctly (like I did) just type down ‘w’ and hit Enter, It will prompt you to confirm just say yes (y)
12. type ‘q’ to quit the application and go see for yourself if your disk appears now in Finder. If it does, go to Step 13. else try disconnecting your external hard disk and reconnecting it. After Mac OS X 10.6.7 it is suggested that you restart your machine and reconnect the disk. If this fails try again from step one. Don’t worry about rewriting the partition table it doesn’t harm your data.
13. You are a hero, no matter if it’s your own disk, you just saved your data!
UPDATE:
If you are having problems with an error message on pdisk saying “the map is not big enough” follow these steps:
Before the analyze step go to GEOMETRY and change the sector size according to the following table:
| Volume Size | Default Block Size |
| <=256 MB | 512 bytes |
| 256 MB <= 512 MB | 1024 bytes |
| 512 MB – 1 GB | 4096 bytes |
Now go back to the ANALYZE step continue from there. Thanks to Stan Alien for the heads up.
Congratulations, and I hope this information is usefull to you now remember to backup your data! Personally I recommend Backblaze.
You can buy me a drink if you’d like to share your joy 🙂
cheers !
Random comment
I really owe you my life, this blog has saved me a lot of time of formatting, repartitioning and installing all my OS’s again. Although I had to dig in some other blogs as well, because it was on my main hard drive, not external, so after I did the very idiotic mistake by deleting my partition table, I couldn’t do it while I’m booting from it. I was also afraid to reset, because I won’t be able to boot from it again.
Finally I managed to boot from the CD, but not using its terminal, there was another way, using CMD+S, it took me to another like-terminal environment which I did all your instructions and it finally worked.
But I still have one small problem, the partition table created is Apple partition map, not GPT, so do you have any idea how to do it?
Again, Thank you so so so much! I really felt like a hero, but I was like Robin to you as Batman. 🙂
Hi PERR0 HUNTER,
Thanks for the post. At step 5 when I hit Analyze, it gives me
Bad MAC partition, invalid block0 signature
and then it gives me Quick Search instead of Quick Analyze, when I click Enter, it seems is going through all the sectors of my 3TB hard drive and it never ends! I’ve been at it for hours and is still at 1%.
Is this the only way to get to next step?
Thanks a lot!
Hi everyone,
I’m trying to recover circa 1.8 TB of data from a 2 TB Seagate Expansion Drive that was accidentally formatted. It began formatting using Mac OS Extended (Journaled) but within three seconds, when the mistake was realized it was unplugged while still mounted.
The drive will not mount so I used Data Rescue 3 to clone the drive to a fresh 2 TB Seagate Expansion Drive and see if it would work. The new drive mounts and shows all the folders and files – but none of them will open. The files are mostly Quicktime Pro Res files, with some as big as 30gb.
I have tried to use TestDisk and the advice here but to no avail. Here are some of the results of TestDisk:
Check the harddisk size: HD jumpers settings, BIOS detection…
The following partitions can’t be recovered:
Partition Start End Size in sectors
HFS 109581 488378646 488269066
HFS 109611 488378676 488269066
HFS 109615 488378680 488269066
HFS 109619 488378684 488269066
HFS 109623 488378688 488269066
HFS 109627 488378692 488269066
HFS 109631 488378696 488269066
HFS 109636 488378701 488269066
HFS 109648 488378713 488269066
HFS 109665 488378730 488269066
[ Continue ]
HFS+ blocksize=4096, 1999 GB / 1862 GiB
When I press continue I get this:
Disk /dev/disk1 – 2000 GB / 1863 GiB – 488378645 sectors (RO)
Partition Start End Size in sectors
D DOS_FAT_32 6 76805 76800 [EFI]
D DOS_FAT_32 12 76811 76800 [EFI]
D HFS 76806 488345871 488269066
>D HFS 91724 488360789 488269066
D HFS 91735 488360800 488269066
D HFS 91749 488360814 488269066
D HFS 91763 488360828 488269066
D HFS 91789 488360854 488269066
D HFS 91804 488360869 488269066
D HFS 91821 488360886 488269066
D HFS 91831 488360896 488269066
D HFS 91840 488360905 488269066
D HFS 91874 488360939 488269066
D HFS 91886 488360951 488269066
D HFS 91890 488360955 488269066
D HFS 91896 488360961 488269066
D HFS 91902 488360967 488269066
D HFS 91918 488360983 488269066
D HFS 91931 488360996 488269066
D HFS 91949 488361014 488269066
And this list goes on and on, this is just a part of it.
I also got this result when I do a quick search of the drive:
check_FAT: Unusual media descriptor (0xf0!=0xf8)
Warning: number of heads/cylinder mismatches 16 (FAT) != 1 (HD)
Warning: number of sectors per track mismatches 32 (FAT) != 1 (HD) EFI System 6 76805 76800 [EFI] check_FAT: Unusual media descriptor (0xf0!=0xf8) Warning: number of heads/cylinder mismatches 16 (FAT) != 1 (HD) Warning: number of sectors per track mismatches 32 (FAT) != 1 (HD) EFI System 12 76811 76800 [EFI] Warning: number of heads/cylinder mismatches 255 (NTFS) != 1 (HD) Warning: number of sectors per track mismatches 63 (NTFS) != 1 (HD) MS Data 2048 488376319 488374272 [Seagate Expansion Drive]
and also this
The harddisk (2000 GB / 1863 GiB) seems too small! ( MS Data 488376319 976750590 488374272
[ Continue ]
NTFS, blocksize=4096, 2000 GB / 1863 GiB
Then today, something seems to have happened – or I must have scanned in another manner as I got this and could list some files:
Disk /dev/rdisk2 – 2000 GB / 1863 GiB – 488378645 sectors (RO)
Partition Start End Size in sectors
D EFI System 6 76805 76800 [EFI]
D EFI System 12 76811 76800 [EFI]
>D MS Data 2048 488376319 488374272 [Seagate Expansion Drive]
D Mac HFS 76806 488345871 488269066
D Mac HFS 91724 488360789 488269066
D Mac HFS 91735 488360800 488269066
D Mac HFS 91749 488360814 488269066
D Mac HFS 91763 488360828 488269066
D Mac HFS 91789 488360854 488269066
D Mac HFS 91804 488360869 488269066
D Mac HFS 91821 488360886 488269066
Structure: Ok. Use Up/Down Arrow keys to select partition.
When I choose to list the files on the Seagate Expansion Drive I get this:
MS Data 2048 488376319 488374272 [Seagate Expansion Drive]
Directory /
>dr-xr-xr-x 0 0 0 21-Feb-2014 11:53 .
dr-xr-xr-x 0 0 0 21-Feb-2014 11:53 ..
dr-xr-xr-x 0 0 0 21-Feb-2014 07:17 Seagate
-r–r–r– 0 0 182 23-Feb-2012 10:07 Autorun.inf
-r–r–r– 0 0 1644118 5-Mar-2012 07:44 SeagateExpansion.ico
-r–r–r– 0 0 156312 16-Jan-2009 08:14 Setup.exe
To my disappointment it only lists the files that were on the original drive before I ever used it. Could these be the problem? Hardly? This is strange? Why does it not list all the files and folder I see when I mount the drive?
I have tried to use perrohunter’s steps, but only get to the second part of step 8 which states:
8.- Issue the command ‘sudo pdisk /dev/rdisk1′ (where /dev/rdisk1 should be the same name you chosed on step 4). If you type the command ‘c’ and hit enter it will tell you the following….
I don’t. First it says “Floating point exception” and when I type c it says “-bash: c: command not found”
Can anyone be of any assistance?
I’m hoping that there is some hope as so many people have been able to fix drives using this blog.
Kindest regards,
Cathal
Given that you can see your files, perhaps all you need is a “sudo fsck.hfsplus -f /dev/sdb1” (if “sdb1” is the partition with your data).
The number in “/dev/disk1” should be a partition number, which is weird considering it appears to find partitions in there. In my case i started testdisk with “sudo testdisk” and selected “/dev/sdb”.
In Testdisk, use the left/right arrow keys to change the D(eleted) signs of the largest non-overlapping partitions. I’d try writing a partition table with the latest version of TestDisk, where “EFI System 6 76805 76800 [EFI]” and “Mac HFS 76806 488345871 488269066” are not Deleted and at least one of them is Primary.
If the hardware is failing, make a full disk image and try to recover on a copy of that (mount the image instead of messing with physical drives of different sizes). If it’s an external drive, a new enclose might help, too. If TestDisk cannot get you a valid partition table, try PhotoRec (by the same people as TestDisk) to recover your important files to a different disk. Here’s a nice guide: https://www.debian-administration.org/article/420/Recovering_from_file_system_corruption_using_TestDisk
Hi! Thank you so much, I have a question for some reason when I type “sudo” I get nothing. What does that mean? I’m new to this and trying to repair an iBook I want to donate. Thanks!!!
Which OS are you using? On Debian-flavored distros of Linux, e.g. Ubuntu, get TestDisk using “sudo apt-get install testdisk”. Keep reading and Googling keywords and error codes.
Hi,
I have a similar problem: My RAID 1 system failed and now I have two 4TB HDDs that won’t be recognized by the system.
I followed your steps, but the pdisk sais “the map is not big enough”.
Tobias-Friedrichs-iMac:testdisk-7.0 iTobi$ sudo pdisk /dev/rdisk5
Edit /dev/rdisk5 –
Command (? for help): i
map already exists
do you want to reinit? [n/y]: y
A physical block is 512 bytes:
A logical block is 512 bytes:
size of ‘device’ is 4294967295 blocks (512 byte blocks):
new size of ‘device’ is 4294967295 blocks (512 byte blocks)
the map is not big enough
Command (? for help): c
First block: 40
Length in blocks: 409600
Name of partition: UNO
the map is not big enough
Command (? for help): c
First block: 409640
Length in blocks: 7813250992
Name of partition: DOS
the map is not big enough
Command (? for help): w
Writing the map destroys what was there before. Is that okay? [n/y]: y
The partition table has been altered!
Command (? for help): q
Tobias-Friedrichs-iMac:testdisk-7.0 iTobi$
Have I done a mistake?
It would be great if you could help.
Thanks a lot in advance
Tobias
“the map is not big enough” means that Length in blocks: 7813250992, is greater than new size of ‘device’: 4294967295 blocks. You cannot map areas that don’t fit on your device.
Check the block size of your disk model
I’m having the same problem. My original partition was the majority, if not all, of my 2 TB portable. The data is only 650GB. Is there no way for me to reverse this?
It is normal to take so much time analysing ? It runs for hours and it is not ready yet.
The quick scan shouldn’t take long, the full scan should take a while
Hi Perro Hunter,
I have a Seagate 125GB external harddrive that I was using to store files that won’t fit on my MacAir (OS 10.11.2 ). I was trying to reformat a 2GB USB stick to FAT16, but accidentally chose my external hard drive when executing the following Terminal command:
diskutil partitionDisk /dev/disk2 1 MBRFormat “MS-DOS FAT16” “NDS” 100%
There was an error, and I thought my external hard drive was not affected. Now I get the following error when I try to access the files on my external hard drive:
“disk you inserted is not readable by this computer”
I followed your instructions, but still get the same error.
The analysis revealed the following:
Disk /dev/rdisk1 – 1000 GB / 931 GiB -1953525167 sectors
Current partition structure:
Invalid FAT boot sector
1 P FAT16 >32M 2 195352166 1953525165
1 P FAT16 >32M 2 195352166 1953525165
Warning: Bad starting sector (CHS and LBA don’t match)
No partition is bootable
Please help?
Thank you.
Hi, so somehow I deleted a mac partition from /dev/disk0
I use TestDisk as recommended and it finds 3 partitions:
Disk /dev/rdisk0 – 2000 GB / 1863 GiB – 3907029168 sectors
Partition Start End Size in sectors
P DOS_FAT_32 40 409639 409600 [EFI System Partition]
>P HFS 409640 1953924223 1953514584
P HFS 1954186368 3906766983 1952580616
If i move my cursor up and down the block size changes:
DOS_FAT_32 = 512
P HFS = 4096
P HFS = 4096
I believe the partition I’m after is the first P HFS
I load up disk:
pdisk: No valid block 1 on ‘/dev/rdisk0’
Edit /dev/rdisk0 –
Command (? for help): i
A physical block is 512 bytes:
A logical block is 512 bytes:
size of ‘device’ is 3907029168 blocks (512 byte blocks):
new size of ‘device’ is 3907029168 blocks (512 byte blocks)
the map is not big enough
I read in these comments that I may need to change my block size to reflect a larger drive. I am fearful that I may irreversibly destroy any chances of my partition recovery if I enter in a different size during the “i” command.
So for a 1TB partition, what do I put for physical block and logical block?
Not sure if you are even following this post anymore but I would love to hear back from you about a similar issue that involves an accidental reformatting of a 4TB USB drive from ex-FAT to MacOS (HFS+?). This is a healthy drive, no new data has been written to it, but I cannot get anything from MacOS apps to restore or reverse the reformatting so I can get back my original 3TB of files. All they find now are RAW, randomly named files and no folder/sub-folder structure. I don’t know if this procedure of yours would work. Maybe you can let me know
Hi Perrohunter,
Thanks for all your outlined steps. I have the similar problem to many others, external hardrive that I have incorrectly removed and now no longer recognised.
I have followed steps 1-6. However on step 6 once analysing it does not present me with any partitions. Just a blank screen with – Bad MAC partition, invalid block0 signature read_part_mac: bad DPME signature (this is after hitting quick search)
Sorry, do you have any suggestions ?
Worked like a charm thanks man !
This is the sort of advice that should be on late night television- but wait there is MORE! Retrieve ALL of your data NOW- no File Carving- no rebuilding Indexes, no FSCK, simply put- its PDISK and its on a mac near you! 😀 (Sorry- complete and absolute file recovery can cause extreme excitement and euphoria)
Hi dog hunter!
I would kiss you if I can! I’ve just recovered a partition that Partition Magic (from a boot cd) dreaded up! It “fixed” an error, and the driver never worked again. I found that the problem was a wrong Partition Table, and your explanation was quite helpfull. Althouth, I was able to do everything from TestDisk! Yeah, its true. After a QuickSearch, I have set the right Partition Types (which the program have correctly detected) and selected the program to write the partition table. The program told me to reboot, and voila! (using a disk formated as GUID with a unique partition as HFS+)
Long live the hunt!
Holy god, you are my hero right now! Bootcamp snuffed my partition table, but the world has been made right again!!! THANK YOU!!!!!!
I manually fucked up my 500gb backup drive when attempting to make Windows 7 read NFS+ drives, and I thought I had lost it all when OS X didn’t seem to read it.
Thanks to you, and TestDisk, I got my data back! I have never been this happy in a long time!
Thank you!
thanks, this worked great. Windows 7 hosed my HSF partition cause it initiated the disk. I tried various tools nothing worked. Followed your step and everything worked, the only thing that i needed to do was scan for my partition a bit it didnt show up in the first quick scan
You are da man! My 1T external became unreadable and unrepairable after an app crashed while copying files. Your procedure worked like a charm.
Thanks for your help. That was excellent. I accidently overwrote my partition table when I connected my osx exernal drive to a XP system and lost all my data. Now it is back …. thanks goodness. Cheers
Does anyone know how do fix the Mac partition from the Windows partition? I already have the log from TestDisk.
Hey Randy ! you could try to use your OS X Installation disc, just insert it, when you get the the main menu, on the apple menu go to Utilities> terminal, and from there use pdisk 😀 ! plz tell me if this worked 🙂 cheers
Hi, I used the installation disk of mac osx after retrieving the data from test disk, booting from dvd. Now the problem is that pdisk gives a “Resource Busy” error. If I try to mount the disk it says “Resource busy” again. I believe there is no partition map (as pdisk says that but he’s unable to write a new one). The fact is that I can’t boot from MacOSX on my macbookpro as it doesn’t see the Machintosh boot drive, but it sees the bootcamp partition (MBR) it start and then Windows sees the Machintosh drive and I can copy the files, but still no luck with booting from it. This is really weird. Any ideas?
testing comments agian
Great info, thanks. I was wondering if it could be done for HFS+.
One thing though, your first screen shot, 36.png, just takes me to the main blog page when I click on it or try to open it in a new tab.
Thanks again for the great tutorial though.
@jim: hey Jim, I’ve fixed that broken link 🙂 sorry I’m transitioning the blog to a new platform.
Cheers
Hi!
Thanks for the tutorial, it really helped me… but unfortunately, I couldn’t retrieve my partition 🙁
All the steps until pdisk worked like a charm. But pdisk, after hitting command “i” tells me the disk is busy and cannot access it. Any ideas how solve this ??
Config: Mac intel dual core (2007) / external HFS+ HD (WD)
Thanks for you help!
Alex
So happy to find this post- gives me hope that I may recover from my hasty mistake (plugging Mac/HFS drive into Windows 7)…
I got Testdisk working, and I was able to “Analyse” my rdisk1. Then when my options are “Quick Search” or “Backup”, either option causes the program to freeze. The log file shows “read err: Resource busy” (preceded by buffer addresses) a ton of times until I quit Testdisk. (I let it run for a few hours last night; no difference)
I was able, however, to view the partition map scheme from Testdisk, so I tried your method in Pdisk.
upon starting pdisk, I get:
“pdisk: Can’t read block 2 from partition 3
pdisk: Can’t read block 2 from partition 5
Edit /dev/rdisk1-”
… and then I can go through the commands. But my results diverge from above:
command ‘i’ –> “map already exists. do you want to reinit?”
command ‘c’ –> when I do the big partitions, I get the “Can’t read block x…” errors again.
Any wisdom?
THANKS. happy 4th.
I’ve had to have TestDisk run a deep search and now I have way too many choices for deleted partitions. Great. We’ll see how this turns out. Good to hear that people out there are getting their data back.
@Mrsupersirk
The issue you are facing is most likely the need to unmount the drive in question before you can perform low-level operations on it. You can open up DiskUtility and click on the drive you are working with and then click the ‘unmount’ button on the tool bar. You could also run the command ‘diskutil diskX unmount’ if you are already in the terminal.
Hi, thanks for the advice. Disk utility took it upon itself to destroy the partition map for my external Hd, I’m currently trying this method as nothing else I was able to find seems to have any suggestions for the issue – hopefully this will work. I was just wondering how long it ought to take pdisk to perform the remapping? (I have a 2TB drive – process is still working and I’ll leave well enough alone for awhile). I’m just looking for a ballpark figure so that I may know whether to assume that it has failed or not.
AMAZING!!!! IT WORKED!!! THANKS FOR THIS, YOURE AWESOME 🙂
hi, i did it but now the disk is not readable by my mac!
help!!!!!!!!!!!
THANK YOU VERY MUCH!!! I could fix my partition table. It was damaged because I used windows to create a new volume. Will never do it again. 😉 Thank you! without your helpful instruction I would not have been able to fix it and rescue my movies and games. 😉
Perro,
I tried to access pdisk from the terminal under the Snow Leopard disc and it said it was an unknown command.
Any thoughts?
Thanks
Mosi
Most of the replies I send are through email 😛 please leave your real email address 🙂
Hello Perro, i send an email with screenshots to your gmail. can you let me know whether you received my email?
kind regards,
Arjan
Thank you for sharing with us your knowledge. you are the best 🙂
thank you very much! It perfectly worked… I recovered a partition with 250 GB of data which disappeared due to a corrupted partition table!
I had upgraded my macbook with a bigger harddisk, with a little help from clonezilla. Bit when I tried to resize the partition with Disk Utility I got an error: “mediakit reports partition (map) too small”
I tried to follow this:
http://info.michael-simons.eu/2010/11/19/migrate-os-x-to-a-bigger-hard-disk/
but I wrote something wrong, and puff! Gone partiotion table ! Hello completely wrong partition table !
Then I downloaded the latest version of testdisk to a usb drive, restarted my macbook with an ubuntu live disk and ran the testdisk in a terminal.
I mounted the usb (mount /dev/sdb1 /media/usb), ran the testdisk utility from the usb stick (in my case testdisk_static), followed your instructions untill step 6.
Then for some awesomeness ! The latest version of testdisk now supports the option to write the partition table for you, based on what it finds analysing the drive ! So I simply choose the “write” option, rebooted and everything worked again !
Thank you so much 🙂
Hi Perro,
I have same problem as your friend facing, after follow your instruction i have facing some problem on the Pdisk command after i run the testDisk, I am using Mac OS X Lion. Is it anyway to retreive back my files in my external hardisk? Thanks.
it’s worked for me !!! Thank you very very much!!!!!!!
@差点要哭出来了… 不小心删除一个mac分区… 找了几个mac数据恢复软件.. 都木有成功恢复, 有的恢复了文件但不能打开…折腾2天了….
今无意中搜索到这篇文章…. 然后又根据这篇文章提供的信息找到英文原版(有图片).
然后… 冒着生命危险参考着原版完成了生平第一次分区表恢复… 更重要的是.. 好几十G的数据终于又失而复得… 真的太感动鸟~ 特意登录来拜谢~
Thanks so much for your tutorial, you are very kind and a gentleman through and through 🙂
Restored my sisters macbook external drive.
Thanks to the author of this guide, he just saved my 2TB external drive, of which yesterday I wipe out its partition map.
I wanted to erase a USB key with Disk Utility, but I was so stupid to select the wrong drive… a couple of second after I realized the error and detached the cable, but the partition map was gone…
Interestlyng, I had to follow a slightly different procedure, because my external drive is formatted with an EFI-GPT map, and not APM.
I followed this guide, but when I tried to create an Apple Partition Map with pdisk it always failed with the error “the map is not bight enough”.
Since APM max size is 2TB, it looks like that my drive is slightly bigger, at least to make pdisk and APM fail.
If someone is interested in make some calculation, this was the output of testdisk:
Disk /dev/rdisk1 – 1999 GB / 1862 GiB – CHS 3905656832 1 1
Partition Start End Size in sectors
P Mac HFS 409640 3905394647 3904985008
Because of this, I had to use the ‘gpt’ command to create a new GTP partition map:
sudo gpt create /dev/rdisk1
sudo gpt add -b 409640 -s 3904985008 -t hfs /dev/rdisk1
As you can see it’s very similar to pdisk, and you need the same information: first block and length in blocks.
After this, I have reconnected the drive to my mac and it worked again. Thanks again to the author, I wouldn’t have find this solution without this guide!
One final notice, now even if the Finder and Disk Utility both can see the 2TB HFS partition, Disk Utility is unable to repair the GPT map because it can’t find any partition.
It looks like that I haven’t perfectly recreated the GPT, but it’s good enough to copy all the files on another drive.
Man, I can’t thank you enough!!
I’ve been strugling with several demos of paid apps and nothing helped, even this tutorial didn’t help until I saw your post. That did the trick!
Thank you, thank you, thank you!!! 😀
Dear Fam,
I have the same problem: “Map is not big enough”. So I tried the got command, but I received the following error: “error: device already contains a GPT”. Do you have any idea, what I could do now? I’d appreciate your help a lot!
Mike.
I went through something similar and was able to fix it by doing the following:
sudo gpt recover /dev/rdisk2
diskutil repairDisk /dev/disk2
(Used “disk” and not “rdisk” with diskutil as the “r version” didn’t show up when running “diskutil list”)
In the end, neither testdisk and pdisk were not utilized in actually fixing the problem.
Fam, you are the bomb.
I had the same issue you did until I tried got and now the drive is back to life. You are a godsend and I cannot thank you enough for posting and sharing your knowledge.
Know that you have made someone’s day. Thank you, thank you, THANK YOU!!!!!
YOU ARE MY HERO, just recover a 3T ex-disk, 3 epsiode documentary back!! and THANK YOU, perro, I really want to hug you guys!
BIG THANKS !!!!! it worked perfectly for me too 🙂
Mmh, para algo asi, no es mas sencillo usar explode()?
VirtualBox destroyed my 2TB external HD along with my 18,000+ family photos… My wife and I were devastated. The HD would come back with an error “Unable to read/ Unknown partition” and “initialize/reformat/ignore messages. Data recovery service quoted me $3000.00 to retrieve my data. After hours trying to use TestDisk I came across your article. With pdisk, I was getting an error about map size… I ran TestDisk again, this time choosing “WINDOWS/VISTA option”… TestDisk told me I needed to set my headers to 32… which I did.. I then was able to “Write” the new partition using “WINDOWS/VISTA” format even though my HD was formatted for mac. A reboot was required but… YEEEEEHAAA my HD is BACK FROM THE DEAD!!! Thank you so much for your article. Without it, I wouldn’t have found out the issues… Thanks from a very relieved novice mac user… using terminal for the first time… and pdisk…
Ahhh! Thank you! ¡Muchas gracias! ¡Eres asombroso!
hey man, got in to trouble!
i have a 500 gb HDD from a lacie EDmini HFS partition on which i fried the usb so i had to access the data your way.
I plugged the HDD in a G4 mac and use the terminal.
everything completed like a charm but the disk did not initialize after restart
🙁
i had 5 partitions but none could be accessed.
help…
Hi!
i’ve been trying to use your method but it doesn’t do any good for me. here’s what i did to screw my life up: completely in a hurry and without any kind of attention i used an “erase” command on disk utility that apparently did not erase the partition, only ALL of the data in it. when i try to recover the partition using your method it only shows me an empty partition…
what am i doing wrong?
thanks a lot man.
running lion.
best!
@Andre, you erased the disk my friend. That is not a partition problem, you just wiped it.
Try data recovery progs, but really, it’s gone.
Hi there,
i tried to re-partition one of existing partition on external hard drive through Disk Utility
after that, some error message appeared and then i restart the mac, and found that my partitions all gone
now i’m trying to use TestDisk, but after i select my error hard drive, the TestDisk just froze and do nothing. i tried to wait, but nothing seems to be happening.
can you help, please ?
my entire data is on that hard drive 🙁
Thanks a Lot..
Aldy
THANKS A MILLION !
worked like a charm!
I am a hero!
And so are you. Un millón de gracias!
Btw: I love you transparent terminal windows that allow us to see through 😉
YOU SAVED MY LIFE! THANK YOU THANK YOU and THANK YOU!!
I bought you a beer 🙂
Hey i try this but i have partition which is HFS n NTFS on my 1TB external HD. but its only choose HFS in the first choice. How i can use it for my HFS n NTFS in the same time when quick analyze…or i must do this twice…..1st HFS n after i repeat again for NTFS???
Hi,
I am a hero as well, looks like the dragon I fight is too tough for me though 🙂
At step 10. when I write the numbers on every of 4 partitions, it says “the map is not big enough” each time.
And when I try to write it down (with ‘w’) it says: “The map has not been changed.”
Any clues on that one guys?
I have a 500 GB disk that only had one partition on it, the “Macintosh HD”. It’s a clean install of Mac OSX Snow Leopard, so I don’t know whether the EFI stuff is on an extra partition. Anyway, when I analyze it with testdisc (version 6.13), it can’t find any partition to repair (is it correct to select “Mac”?
It says:
Bad MAC partition, invalid block0 signature
read_part_mac: bad DPME signature
When I select Analyze, it slowly counts up the cylinders and after half an hour, I’m still stuck at 00%, but it can find some stuff:
Disk /dev/rdisk1 – 500 GB / 465 GiB – CHS 976773168 1 1
Analyse cylinder 7208960/976773167: 00%
HFS 4121592 980222935 976101344
HFS 4122752 980224095 976101344
HFS 4123776 980225119 976101344
HFS 4126584 980227927 976101344
HFS 4128264 980229607 976101344
HFS 4130200 980231543 976101344
HFS 4132592 980233935 976101344
HFS 4137616 980238959 976101344
HFS 4142720 980244063 976101344
HFS 4146816 980248159 976101344
HFS 4151464 980252807 976101344
HFS 4158352 980259695 976101344
HFS 4164920 980266263 976101344
HFS 4172128 980273471 976101344
All I need is the info from Step 6 so I can enter it into pdisk. Is there any way to get it without scanning the hard drive for weeks?
@FAM, I found the solution to your problem. I too was experiencing the error, “the map is not big enough” and couldn’t rebuild my partition map.
I found this site: http://forums.macrumors.com/archive/index.php/index…/t-1140673.html and followed his instructions to a T. (the critical instructions are in the next 2 paragraphs)
“First, you’ll need to figure out the disk number of the hard drive. If you’re booted from the machine (rather than a different machine, using the drive as an external), it’s going to be /dev/disk0. The following will rewrite the partition table to near-default (possibly a little bigger primary volume):
sudo dd if=/dev/zero of=/dev/disk0 bs=512 count=10 conv=sync,noerror
sudo gpt destroy /dev/disk0
sudo gpt create /dev/disk0
sudo gpt add -i1 -b40 -s409600 -tC12A7328-F81F-11D2-BA4B-00A0C93EC93B /dev/disk0
sudo gpt add -i2 -b409640 -t48465300-0000-11AA-AA11-00306543ECAC /dev/disk0
(I typed in the commands EXACTLY as he specifies – just be sure you know the correct name of your disk. Mine was just like he shows /dev/disk0 My disk was connected externally to my working MBP)
Once I finished entering the last command in Terminal, the disk immediately mounted on my desktop.
Next, I tried to use Disk Utility to repair it like he mentions, but it failed. I then used DiskWarrior and THAT finished up the repair just as he said.
My disk works fine!! It mounts no problem. No data lost.
Hey Master… I’m on the same situation with my disk, I did everything you said but I get the prompt saying: The disk you Inserted was not readable by this computer, the option to
Initialize – Ignore – or Eject!
What to do, I’m Running OS 10.8.5
Without seeing the Disk I can’t run Disk Warrior, it doesn’t appear on the Menu!
I’m simply about to cut my veins!! ;-(
My whole VIDEO LIBRARY FROM MY BAND IS ON THIS DISK, ! ;-(
Amazing!!! Thanks for such great advice. A true Hero 🙂
Hi,
I have some trouble with my Macintosh HD… can’t boot any more
I used test disk as discribed bellow… but wenn I run
pdisk /dev/disk0 (or /dev/rdisk0) I get the following message:
pdisk: can’t open file ‘/dev/disk0’ for writing (Resource busy)
I started my Macbook Air (first gen) from USB-Stick with Snow Leopoard on it and run test disk via terminal an disk as well
I get Resource Busy when I run pdisk
Any help would be happily welcome.
Thank in advance.
I need a help. I’m trying to expand my boot camp windows partition, but I converted my disk to a dynamic disk accidentally. Now my entire disk in my iMac is a dynamic disk, and I’m not able to boot to OS X. How can I revert the process without the loss of data? I’m able to boot Windows 7 but I don’t know how to resolve this problem without losing all my data in mac partition. I tried use TestDisk but I don’t understand how to use it especially when choosing which drive/partition and partition type. I’m not sure of it.
Thanks for your help
hi
i borrow my sister laptop md313 and want to install windows 10 ,accidentally made a volume in disk management in windows,then mac doenst boot..just windows can use……….pleeeeeeez tell me what should i do with this program or anything else thanks…….
man,i’m completely fucked up,please help me
I know it was seven years ago about give or take, but you did figure out to just hold the option button down when the Mac starts to boot into anything that can?
Clear, simple instructions let me recover after disk utility on PPC wiped the partition map when I tried to manipulate a drive with multiple partitions with different filesystems on them.
Thanks for posting this. Saved me 630Gb of data.
Hi, Please help me, my 1TB drive can not read, I have on it from Time Machine backups,
I used a test drive and wrote me this: Bad MAC partition, invalid signature block0
read_part_mac: bad signature DPME
thanks for any help
Just a remdinder I answer most of the comments via email 🙂 so you should use your real email on the comments hehe
cheers
After step 9. there is “can’t open file ‘/dev/rdisk0’ for writing (Resource busy) similar to @Mrsupersirk. I’ve tried also ‘gpt’. Nothing. Please help……
Im having the same problem as Jakob at the part where it scans the drive but shows 16% after nearly a day. Is there any hope left or could i just map the whole drive as one partition? It only had one when the data was lost.
this is great! but i have a problem. i am trying to repair a g-tech g-speed q and it is setup as a RAID array. it has four drives and they all show up when i analyze. i did just pick one of them and tried to follow the instructions to completion but then i run into the “the map is not big enough” error.
so, does it matter what drive i pick of the four? i saw the instructions from @drew )http://forums.macrumors.com/archive/index.php/index…/t-1140673.html) but before i do that i want to be sure i know which disk to select of the four that are showing up.
thanks!!
Hello and thank you so much for your help!
I have an issue though – when I get to step 9, my command terminal says: “can’t open file … for writing (permission denied)
It seams even using the sudo command that I can’t write restored partition to the drive? I have been searching for over a day now trying to recover this drive and I don’t know what to do… if you have any insights that could help I would appreciate it insanely… thank you again!
I’m having the same problem as some, where it’s taking a ridiculous amount of time to scan the disk. I opened the Console and it shows hundreds of read errors per second. I just left testdisk running overnight and it was still at 00%
If my partition used to be GUID, it’s considered Intel, correct?
I have this problem, but there’s not a response in any comments:
pdisk: can’t open file ‘/dev/disk0’ for writing (Resource busy)
please help!
I respond most of the comments via email 🙂
hi
i borrow my sister laptop md313 and want to install windows 10 ,accidentally made a volume in disk management in windows,then mac doenst boot..just windows can use……….pleeeeeeez tell me what should i do with this program or anything else thanks…….
man,i’m completely fucked up,please help me
i have same problem Agha said to you……
I’m trying to expand my boot camp windows partition, but I converted my disk to a dynamic disk accidentally. Now my entire disk in my iMac is a dynamic disk, and I’m not able to boot to OS X. How can I revert the process without the loss of data? I’m able to boot Windows 7 but I don’t know how to resolve this problem without losing all my data in mac partition. I tried use TestDisk but I don’t understand how to use it especially when choosing which drive/partition and partition type. I’m not sure of it.
I’m also getting the resource busy message when pdisk’ing into /dev/disk0, any suggestions?
I’m also getting the resource busy message when pdisk’ing into /dev/disk0, any suggestions? Cannot find a solution
HOLY MOTHER OF GOD THIS WORKED!!!!! I cannot believe it! I had tried different softwares at $100 each all claiming to be able to restore lost partitions (and sure they would DETECT the lost partitions but there was no hope of actually been able to RESTORE them!) but none of them did anything like this! Literally when I finished all the above steps my entire hard drive (1 Tb Lacie) was restored with everything EXACTLY the way it was before the hard drive crashed!
I cannot thank you enough – seriously you are a life saver and just made my week!
Keep up the good work!
Cheers 🙂 ! 🙂 !
Hi,
i think bootcamp windoz has blew up my partition scheme, so i tried your steps, but now i’m getting the same error as some people described. The “pdisk: can’t open file ‘/dev/disk0’ for writing (Resource busy)”
plz, help…
You guys shouldn’t be using /dev/disk0 as that’s probably the main disk in which your OS X is running, you should be using something different such as disk1, disk2 and so on…
cheers
testing
Man, you are my hero!!! I tried every kind of recovery software, i’ve also bought DataRescue3 for Mac, didn’t work, but now i have 70% of my partitions restored, i don’t know what happened with the other 30%, but it’s already perfect. Thank you so much, brazilian regards, Rodrigo Maia.
Tnx to the author and tnx to Fam: on my 2TB hard disk i have repait partition table with gpt command
can you describe how you used gpt ?
Thanks MAN! It worked on my HFS partition!
For a strange reason disk utility saw it as unallocated space….
Just one problem…
I had two NTFS partitions together with HFS with windows and after following your guide those partitions are unavailable…
and disk utility seems to see them as HFS partitions….
any suggestions?
Once again THANK YOU!!
Friends, please help.
I do not know how to solve this problem. I drive RAID0 array, 8TB. TestDisk gives the following parameters:
/dev/rdisk3 – 8001GB/7452 GiB CHS 2743214502 1 1
START END Size
P EFI System 40 409639 409600
P Mac HFS 648264 15628092823 15627444560
By doing everything as the instructions on the page, an error pops up:
“The map is not big enough”.
How to perform the entire process, step by step.
Stress eats me because I have important files.
Please help.
Chris
You are AWESOME! Certainly my HERO!
Your tutorial did the trick mate! Thank you so SO much!!
It worked a treat!!!
PS.
Just a word of warning for others in case they are thinking of using other recovery software. I bought Disk Drill in a panic buy yesterday. It recovered the files, took 17 hours and they did not have ANY filenames and NO folder structure! What a useless piece of software! I had 300,000 files with no names!!! Utter rubbish!
Hi, I have the same RESOURCE BUSY problem, can you help me please?
Help please.
I am in a similar position I started formatting my back up drive by accident, here is what I started with:
2TB WD external
– 500GB (A) up front partitioned in ExFAT
– 1.5TB (B) partitioned in Mac OS Extended (Journaled)
I accidentally starting erasing the 1.5TB using MS-DOS (FAT) and pulled the plug seconds after initiating the process. So far I have been able to verify that most of the data is still there from what I could tell utilizing (EaseUS Mac Data Recovery Wizard) I am now utilizing the TestDisc to try and repair the partition. Any help with this issue would be greatly appreciated
Thanks in advance
you are an uber hero. One you were a hero to your friend, then two you were a hero to people you don’t know. Then three: you gave us the power to be heros too.
Good work!
Hi.
I did exactly what @Barry (2012-03-13) did.
and I have done the testDisk scan AND deep scan, and now I have a lot of options as per @ (Noahness 2011-07-07.)
I am just wondering if I should copy and enter ALL these info, or if I should enter every-other one, since there are some duplicates on these results.
I have copied and pasted the screen results below, I’d really appreciate your guidance!
Disk /dev/disk1 – 2000 GB / 1863 GiB – CHS 390702916811 Partition Start End Size in sectors >D EFI System 40 409639 409600 [EFI] P EFI System 46 409645 409600 [EFI] P Mac HFS 445649963 819998940 374348978 [7] D Mac HFS 819998937 1194347914 374348978 [7] D Mac HFS 828521845 1912924457 1084402613 [] P Mac HFS 841226752 2795728924 1954502173 [F]
Structure: Ok. Use Up/Down Arrow keys to selectpartition. Use Left/Right Arrow keys to CHANGE partition characteristics: P=Primary D=Deleted Keys A: add partition, L: load backup, T: change type, P: list files Enter: to continue
O gerenciador de discos do windows 7 (via bootcamp) alterou o tipo das partições do meu mac, onde todas ficaram inutilizadas. Tentei diversas ferramentas, inclusive o proprio TestDisk, mas as dicas complementares deste blog salvou meus dados. Valeu demais!
I’m having the same problem with resource busy. I’m booted from the Snow leopard install disc. HFS+ partition table won’t boot after re-imaging with clonezilla. Any ideas?
Thanks.
hi…i’ve got a little problem with my WD 2TB hard disk…it’s full of my data, photo and video but when i try to copy come files, an error -36 appers from the finder…this happend only with some files, not all…i’ve tried to repair with disk util,but nothing works, the error -36 still apper…tried to fix with partedmagic, but nothing went well…so i want to try to fix the partiton that maybe solve the error -36 from the finder and i read this article..
So, I only want to know one thing: the pdisk command will delete all my data(documents,photo,video) or it will preserve them and fix the partition!?
thanks for the reply…please help me folks!
Hi,
As I can’t boot OS X and I don’t have a recovery disk right now, can you tell me what is the linux equivalent of pdisk? Also, will it work on an MBR formatted disk?
Thanks.
Hi,
As I can’t boot OS X and I don’t have a recovery disk right now, can you tell me what is the linux equivalent of pdisk? Also, will it work on an MBR formatted disk?
Thanks.
Need a little help here, Im stuck right after Step 7, apparently I am not a “man” haha. When I close Testdisk and enter “sudo pdisk /dev/rdisk1” into Terminal, and I get “Floating point exception”. Any help would be appreciated, I have over 500gigs that I need to recover, and it took me 5 days to run Testdisk!
This is definitely the most helpful site I have seen about using TestDisk and pdisk, and is really helping me.
I have the same problem as Jay, I get
pdisk: can’t open file ‘/dev/disk1’ for writing (Permission denied)
after entering i.
Funny, because last night it worked, I was getting the place to enter First block, but I just went back to TestDisk one more time to check the figures, and this time it is different.
Also, does it matter if you analyse/try to restore disk1 rather than rdisk1.
Many thanks.
Hi I am having the same “can’t open file ‘/dev/rdisk1’for writing (Resource busy)” error at step 9. What do I do here? Also, can you tell me the difference between disk1 and rdisk1? I selected rdisk1 as you did, but I’m not sure why.
I am trying to recover an exFAT partition that disappeared after doing an Apple update. The first (HFS+) partition still works fine – it has Lion and applications. The exFAT was my data partition, and then I had unpartitioned space for a future BootCamp partition. Now DiskUtility shows the Lion partition and then a MS-DOS(FAT) partition called DISK1S4 taking up the rest of the space on the drive.
I have attached it to a different Mac to do this, so I am not booting from the drive I am trying to repair.
Thanks so much!!
I got around the Resource Busy problem by going to Disk Utility and unmounting the partition. Then the command worked.
However, now in step 10, I get
Command (? for help): c
First block: 40
Length in blocks: 409600
Name of partition: EFI System Partition
requested base and length is not within an existing free partition
Bad size
Am I supposed to skip the EFI System Partition, or what? I know the numbers are correct, because I had copied and pasted the info to TextEdit and copied and pasted the values from there.
1 P EFI System 40 409639 409600 [EFI System Partition]
2 P Mac HFS 409640 684101047 683691408 [MacIntoshHD]
3 P Mac Boot 684101048 685370583 1269536 [Recovery HD]
4 P MS Data 781971456 1465147391 683175936 [Data]
A physical block is 512 bytes:
A logical block is 512 bytes:
size of ‘device’ is 1465149168 blocks (512 byte blocks):
new size of ‘device’ is 1465149168 blocks (512 byte blocks)
Did you ever figure this out!? I am getting the same issues you got and can’t fix the issue! Thanks so much!
William
For you and others coming across this the solution is just to ignore the “requested base and length…” message:
http://fillwithcoolblogname.blogspot.co.nz/2011/04/repairing-mac-hfs-partition-table.html
check my response to Michael Sprague below.
This post is a potential lifesaver.
But please would would you update the main body of the text to include the warning about having to use gpt instead of pdisk on disks with GPT partition tables?
I followed your instructions to try to recover a 3TB drive which Disk Utility said needed to be initialised, including using pdisk to do the recovery (because I hadn’t read as far as the post from Fam on
2011-10-23).
Unfortunately although pdisk had failed with the partition map not big enough error, it had converted the partition scheme to APM.
And then the gpt command wouldn’t add partitions or create a new map (not even with the -f force options) or destroy the existing map.
Eventually I found this reference http://apple.stackexchange.com/questions/17845/how-do-i-change-a-disk-partition-map-scheme-from-mbr-to-guid-partitions-table
which said that iPartition http://www.coriolis-systems.com/iPartition.php was able to change the partition scheme (including from APM to GPT).
Luckily I had purchased iPartition some time ago so I gave it a try.
After setting the partition scheme back to GPT, I used the gpt instructions above to add back the partitions based in the information that testdisk had displayed.
Now all my partitions seem to be readable again.
Amazing!
I have managed to get to step 7. When I try to “Issue the command ‘sudo pdisk /dev/rdisk1′” in Terminal Password: pops up
Nothing I have tried works.
I have never used Terminal before and fear I’m not entering the command at the right place.
Analyse on TestDisk says:
Disk /dev/disk1 – 1000 GB / 931 GiB – 1053525168 sectors
Analyse cylinder 262144/1953525167: 00%
Read error at 260160/0/1 (lba=260160)
The external HD is a Lacie and I use a MacBook Pro older model. I would be eternally grateful for any help you can provide. Thank you so much for your time!
Hi Perro
I have a similar problem to George Hickman (2012-07-18), I enter the numbers just as they are but it tells me they are a bad size.
Edit /dev/rdisk1 –
Command (? for help): c
First block: 943125381
Length in blocks: 730761324
Name of partition: Lacs SG
requested base and length is not within an existing free partition
Bad size
Command (? for help): c
First block: 1803089310
Length in blocks: 842665196
Name of partition: Lacs SG 2
requested base and length is not within an existing free partition
Bad size
Command (? for help):
What am I doing wrong? or what can I do differently?
Thanks so much for your time and help
Hi L Cox,
Try using /dev/disk1 instead of /dev/rdisk1 it might work, have you confirm with disk utility that you are using the right disk?
Thank you!!!! I nearly lost 12 years of my work, which I stupidly kept storing for the past 2 years at Iomega external HD without additional backup. Apparently if you forget to unmount an external HD under Mac OS it could damage HD’s partition table. That’s exactly what happened this evening, when my incidentally knocked off a USB cable [arrrhhhhh]. After re-inserting the HD back I saw that scary message “the disk you inserted was not readable”. Following your suggestions I managed to get all my data back. THANK YOU FOR SHARING THIS WITH THE WORLD!
really thanks sir…
you save my life… however i use difrent method… but you inspired me… you are real hero…
thanks
Hi Perro
I am attempting your instructions but when I get to step 4, the Seagate GoFlex 4TB drive does not appear. I just see the imac’s hard drive. On the terminal it mentions that I should be the root user. I assume I am. There are no other drives connected at this time. What can I do to have Testdisk detect the damaged disk? It appears on system profiler.
Many thanks!
John
Hye Perro,
I tried to do exactly what you wrote down. Im having some difficulties though. I know that my WD hard drive used to be MAC OS Extended (Journaled), and I connected it to windows 7 via bootcamp yesterday and i guess thats when everything went wrong. Some of the messages that appear on the terminal was that the is not writable. when i chose the dev/rdisk1 one option, i chose apple mac partition, but no partition was shown. When i chose the option NONE though, there is a partition that says
“P Unknown Start 0 end 429463199″….
Does that mean everything in my hd has been deleted? Im kinda stuck at there… I still tried using that pdisk command though, since i have the start block and end block values, but when i tried calling for the commands, the commands could not be found..
Any idea on this?
Many thanx….
Ary…
Hi Perro,
Thanks for the info. I have run into a problem though and it doesn’t seem to be working for me. The first time I ran through the process the screen shots were similar to yours but nothing happened.
So I tried again and the following times the testdisk screen showed me more partitions at the beginning, before analyzing the partition (partition map, etc). I could still do the steps. Once analyzed and in terminal, the info changed from what it showed in step 8 before. It woulnd’t say that there is no valid block.
I can still go through the steps, but it asked me to initialize first.
I do and still no success.
Any help or ideas would be appreciated.
I am working on a 16gb flash drive. I ejected it from my computer, the icon disappeared from the desktop and then i removed it but when i plugged it in to my laptop i got the error message.
Thanks
Yes, I can confirm, you’re a Hero!!!
Seriously, this was actually soooo easy compared to waiting hours upon hours for those pay-for apps to scan and analyse. Ok, so some of them give you the volume names but then that costs $90+
The problem I had was a home made RAID Box using a SATA Raid Bridge board from SPAN.com (http://www.span.com/product/Firewire800-USB2-eSATA-Bridge-Board-UFS-DSATA210-PLX-Oxford-OXUFS946DSE-LQCG-chip-for-2x-SATA-HD-Normal-RAID~34369).
I previously had a pair of 500Gb SATA drive in RAID-0 as a backup/temp storage location while I was shuffling files around various machines and external disks.
My Mac Mini’s hard drive starting failing (S.M.A.R.T Attribs. showing issues and machine slowing with lockups too). So I used the Bridge Controller board with another SATA drive to backup the Mini – but I needed to change the Mode of the board from Raid-0 to ‘pm’ (Just a Bunch Of Disks – JBOD) as there was just one drive connected. After completing the backup, I forgot what the previous setting was and the board re-initialise the pari of 500Gb disks!
After hours of downloads and testing apps. – I’m a cheapskate as it shouldn’t be that difficult to rebuild a partition table with the right tools – my Google Foo got refined and I found this blog after reading about TestDisk.
So, with the AppleXSoft app’s scan results, I could match the partitions listed by TestDisk by size (length / 2 / 1024 / 1024 = Size in Gb .. first /2 is 512 byte per sector). Then I named the partitions I re-created with the names listed by AppleXSoft’s app. …or used ‘n’ from TestDisk’s menu to change them from ‘One’, ‘Two’ and ‘Three’, then wrote the changes to the disk. Bare in mind, if you had spaced in the partition names, you need to enclose it with double-quotes. e.g. “Recovery HD”
Once again, thank you Perro, faultless – just a shame TestDisk doesn’t write to HFS+ and still need to use pdisk. Incidentally, it’s back on Mac OS X Mountain Lion – I read Apple apparently removed it, or maybe the Migration Assistant copied it from my old MacBook Pro which initially had Leopard followed by Snow Leopard and Lion OS Upgrades).
Hi, can I use this guide on Ubuntu or it is only for Mac?
Thanks a lot!
Hey man,
I recently had my USB 1 TB external hard drive get unplugged accidently, and since then I’ve had the “unreadable” error on my MacBook. I tried out this application, and while I’m not the most handy using Terminal, your walkthrough was perfect. The only thing is, it didn’t work. And I’ve tried now maybe four times. I was wondering if there was any further help you have to give as I want to try to recover what’s on this drive before just abandoning ship. Thank you again!
That simple? LoL!
Hi Perro Hunter,
Same issues with the others
“requested base and length is not within an existing free partition”
tried both rdisk1 and disk1
It worked the first time but half way down entering it I missed a number in the partition start so had to start over.. now its happening every time.
all I did was quit terminal and start over.
Any idea?
Maybe the resource stayed open, try re-entering the partition table with pdisk
Work perfectly. Thank you so much!
I’m glad 😀
You just saved my life. Thank you very much.
You are very welcome 😀
I’m also running into problems at Step 9.
“pdisk: can’t open file ‘/dev/disk1’ for writing (Permission denied)”
I’ve tried /dev/disk1 as well as /dev/rdisk1
Also, ‘sudo pdisk’ returns “pdisk: Can’t read block 0 from ‘/dev/disk1’”
Has anybody been able to solve this yet?
Does the drive makes noises?
It makes pretty much the same noises as a healthy drive, nothing out of the ordinary! I “lost” the partitions on the drive after I had to forcefully power off my mac because it froze, so I am assuming the drive isn’t dying from old age.
Im also having this problem:
“pdisk: can’t open file ‘/dev/disk1′ for writing (Permission denied)”
I also tried with /dev/rdisk, same error..
Any solution to that?
Have you tried using sudo? are you sure it’s disk1?
I put my 10.4.11 HD into the freezer. Clicking sound went away but I got the error: “The disk you inserted is not readable by this computer”. Because I’ve read there is only a short time to retrieve my data and every attempt causes greater damage to the HD, I’d like to know exactly what I should do before I do it. After the HD thawed, clicking started again. I now have a new HD in my mac but the OS is different from that of my clicking HD. Is my data recoverable? The experts couldn’t get it off the clicking HD.
– Some have suggested going into TERMINAL and trying “diskutil list”, “sudo gpt recover /dev/(insert your hard disk ID)”.
– Another suggestion is “diskutil repairDisk /dev/disk[Number]”
– Now I see the Testdisk option of this article.
Any diagnosis/help would be much appreciated.
Hi,
Thanks for your great tutorial. It worked well for me up until the pdisk part. I got the same error that others had (can’t write to the disk, permission denied). I tried the gpt command as well, but had the same problem there.
I checked to be sure and the disk is not mounted. But Disk Utility does say that it is “read only,” for some reason.
Any advice?
Thanks again!
Perro,
Great instructions, and extremely helpful in correction a (incredibly) scary problem (corrupted partition table). Your detailed instructions, screenshots, and links to the tools (TestDisk) were awesome!
I had almost given up as permanently lost (or, at least, terribly damaged and leading me towards hundreds of hours of recovery, renaming and restructuring work) almost 11 years worth of digital history (pictures, music, documents, applications, etc.), and you saved me!
So… THANK YOU!
Khalid
Amazing tip. I haven’t read all comments, but TestDisk now can write the partition table. So no need to use pdisk anymore.
Done all of that, but the disk doesn’t show up in finder.
Tried to do it again and this is what I’ve got from terminat: http://cl.ly/Oah9
“map already exists
do you want to reinit? [n/y]:”
Could you give a hint what should I do next?
Thanks
Another thing when I’ve tried to do it again from step1: http://cl.ly/OaDV
I remember that even the first time I’ve got the “the map is not big enough” message – maybe this is the problem?
thanks again
p.s. here is a print screen of my test disk info http://cl.ly/Oa8m
Oh My God THANK YOU!!!
I was trying to get my hfs+ external HD to work on a win7 computer and when I tried to reconnect it to my mac it said “Nope, can’t read it…”. And I had a near meltdown… When I was solid enough again to start googling I nearly spent 99€ for nothing. Thankfully I found your post!!!
Oh my God this is so freakin’ satisfying! Thanks a million and once!!!
Very Happy Greetings from Hamburg Germany!!
Hey, man, just to say “thank you”. My friend came over with her non-booting Macbook Pro, I pulled the harddrive connected to my Air via usb and “boom”, no partitiions. I thought “what the…” and reading your case was almost like mine.. except, I put the disk back on and still no boot, not recognized (booted from MLion pen, no disk shows up). Pulled it off again and the partitions were still there, so we just made a backup copy of all the info and its up for repairs (second Mac I know that has the flat cable problem in like two weeks! – I’m guessing it’s the problem on this one, since everything else seems fine).
A great big thanks to you. Macbook pro HD partitions missing after a bios fallout. Unallocated disk with only 32MB showing in disk utility. Recreated exactly as it was before this barny. Cheers.
You’ve just saved my life.
MERCI!!!!!!
You really save my life!. Thanks a lot!!
You really save my life!. Thanks a lot!
Repair a Mac OS X HFS+ Partition table | Filemaker Info
I’ve spent the past few days calling around to different data recovery places, and they all told me it was useless, and if it wasn’t then I would be looking at about $600+ to get all the shows, movies and Uni work off my HD. I really needed it back, but I’m a student who doesn’t have $600+ lying around. So, I tried this
AND IT WORKED 😀
Seriously you have no idea how loudly I am screaming right now. I haven’t been able to access this thing for MONTHS, and I was a week off walking out and buying a new one and just starting over.
Thank you SO SO SO SO SO MUCH! AHHHHH!
hey there. i’m not sure how current this article is, but noticed you mentioned emailing you so thought i’d give it a shot.
I have a 250gb seagate external that I had allll my files on from college. I was working on a windows pc at that point. i got a mac and plugged it in and was able to see everything. I transferred one folder and all worked well. I later reconnected my device to my mac and it said it could no longer be read. my HD has been sitting in a drawer for the past 5 years as i couldn’t figure out what to do.
Will this tutorial be a possibility for me with my current mac? will it hurt the HD in anyway if this technique doesn’t work?
thanks, greg
Refusal to Boot if NON-BOOT internal HD is plugged in
Scared the hell out of me doing it – but it worked! Thanks a bunch!
Hi, great post!
Same problem like Tamar here (Can’t read block, Unable to write block). Any Solution?
Disk /dev/rdisk4 – 3000 GB / 2794 GiB – CHS 732566646 1 1
Partition Start End Size in sectors
>P HFS 51206 146679629 146628424
P HFS 146712398 732533871 585821474
———–
A physical block is 512 bytes:
A logical block is 512 bytes:
size of ‘device’ is 0 blocks (512 byte blocks): 732566646
new size of ‘device’ is 732566646 blocks (512 byte blocks)
Command (? for help): c
First block: 51206
Length in blocks: 146628424
Name of partition: tm
pdisk: Can’t read block 2 from partition 2
pdisk: Can’t read block 2 from partition 3
Command (? for help): c
First block: 146712398
Length in blocks: 585821474
Name of partition: data
pdisk: Can’t read block 2 from partition 4
pdisk: Can’t read block 2 from partition 5
Command (? for help): w
Writing the map destroys what was there before. Is that okay? [n/y]: y
pdisk: Unable to write block zero (Invalid argument)
pdisk: Unable to write block 1 (Invalid argument)
pdisk: Unable to write block 2 (Invalid argument)
pdisk: Unable to write block 3 (Invalid argument)
pdisk: Unable to write block 4 (Invalid argument)
pdisk: Unable to write block 5 (Invalid argument)
pdisk: Unable to write block 6 (Invalid argument)
The partition table has been altered!
Tank you very much!
same problem here. how can we solve?
Please add me as another happy user of your methodology. It worked like a charm and this has restored my faith in the Interwebs being a force of good. Merci beaucoup!
This worked great, I think! I would just add that I had to modify your instructions a bit. I was trying to recover a 2TB drive with two partitions, and whereas you skipped over the block size prompts in pdisk, I had to change those. I used 4096 bytes per block, which seems to have gotten it to work. Before I was receiving “the map is not big enough” errors from pdisk.
This table is where I got the correct block size: http://support.apple.com/kb/TA37344
Can you post a screen shot ? We’ve made it to step 10, but can’t figure out what to put for first block ????
pdisk: No valid block 1 on ‘/dev/rdisk1’
Edit /dev/rdisk1 –
Command (? for help): c
No partition map exists
Command (? for help): i
A physical block is 512 bytes:
A logical block is 512 bytes:
size of ‘device’ is 3907050332 blocks (512 byte blocks):
new size of ‘device’ is 3907050332 blocks (512 byte blocks)
Command (? for help): c
First block:
Hi Andy,
Can you explain this? I am having the same problem.
I have a 2TB disk with one partition but it starts at 3907003948 with a size of 9396 it looks very small to allow the 2TB.
One additional tip: you can have multiple terminal windows open. Just hit cmd-N.then you won’t have to write anything down since you can simply run the pdisk cmd in another window, referring to the testdisk window when needed.
Also–and this may have been covered–you’ll have to make sure that the Superuser functionality is turned on for your Mac. (See this — http://bit.ly/1988gyE — apple support doc since it’s different for various flavors of OSX )
Well, The TestDisk part worked for me, but I’ve gotten lost on the p(diddy)isk section.
My array is an 8TB RAID 6 (so two parity drives, 6TB of data). I just had to replace a bricked drive and now, even though the array has been rebuilt, OSX can read but not write. Every reboot gives me “OSX can not repair this drive” error.
SO I’m working my way through your page, but when I hit “i” I get “map already exists do you want to reinit? [n/y]:” —and I’m note quite prepared for the risk of y 🙂
When I use “c”, I get “The map is not writable.”
Hi, i have same problem that many people asked in comment section.
pdisk: can’t open file ‘/dev/disk0’ for writing (Resource busy)
it happened, now what should i do? i didn’t find anything in comments, hope you’ll reply..
Oh my goodness! This is probably the most valuable thing I’ve ever found on the internet.
Thank you VERY much for what has been a PERFECT writeup on what to do when your partitions suddenly disappear.
I’ve had the same issue to Scarlet, but her question was never answered so hoping someone will answer mine. I get through step 7 but when I go to Issue the command ‘sudo pdisk /dev/rdisk1′ using the correct disk name it asks me for a password, but I’m unable to type anything in anyway so that’s where I end. I’m not well versed in using Terminal so maybe that’s part of the issue, but I’d appreciate some help! Thanks!!!
Nevermind! The password just doesn’t show even though it IS typing in .
Having the same issue. I don’t understand most of what I’m reading and guess it’s time to start reading on how to use the Terminal. Here’s what I typed
diskutil list /dev/disk0
Then this popped up
#:TYPE NAME SIZE IDENTIFIER
0:GUID_partition_scheme *250.1 GB disk0
1: EFI 209.7 MB disk0s1
2: Apple_HFS Macintosh HD 249.7 GB disk0s2/dev/disk1
#: TYPE NAME SIZE IDENTIFIER
0: *2.0 TB disk1
I tried this next (2 TB is my external Graid3 drive)
diskutil repairDisk /dev/disk1
NOTE: repairDisk is deprecated, use repairVolume instead.
Error starting filesystem repair for disk1: Unrecognized filesystem (-9958)
Next
diskutil repairVolume /dev/disk1
Error starting filesystem repair for disk1: Unrecognized filesystem (-9958)
sudo pdisk/dev/rdisk1
Password:
sudo: pdisk/dev/rdisk1: command not found
I have no clue what to do, or how to run the program I download from you first step. Kind of just poking around at this point and know that’s not a good thing.
Hi Perro,
You are the man! Yesterday I messed up an HD with footage and projects on it that weren’t backed up and I felt like an idiot. Thanks to you and TestDisk, I was able to repair it with the help of a friend. Saved weeks of work and footage that could have been lost forever. Keep up the good work! I do feel like a hero now 🙂
Hey Perro! Thanks for this resource. I’ve found it very helpful! I’m two days into a scan and have a question. I’ve got a HFS 2TB RAID 0 drive that isn’t mounting. I’ve run testdisk and so far these are the results:
(I’m trying to fix –> Disk /dev/rdisk4 – 2000 GB / 1863 GiB – 3907050332 sectors, sector size=512)
TestDisk 6.14, Data Recovery Utility, July 2013
Christophe GRENIER
http://www.cgsecurity.org
OS: Darwin, kernel 10.8.0 (Darwin Kernel Version 10.8.0: Tue Jun 7 16:32:41 PDT 2011; root:xnu-1504.1
Compiler: GCC 4.0
Compilation date: 2013-07-30T14:08:37
ext2fs lib: 1.41.8, ntfs lib: libntfs-3g, reiserfs lib: 0.3.1-rc8, ewf lib: 20120504
Hard disk list
Disk /dev/disk0 – 2000 GB / 1863 GiB – 3907029168 sectors (RO), sector size=512
Disk /dev/disk1 – 1000 GB / 931 GiB – 1953525168 sectors (RO), sector size=512
Disk /dev/disk2 – 1000 GB / 931 GiB – 1953525168 sectors (RO), sector size=512
Disk /dev/disk3 – 640 GB / 596 GiB – 1250263728 sectors (RO), sector size=512
Disk /dev/disk4 – 2000 GB / 1863 GiB – 3907050332 sectors, sector size=512
Disk /dev/rdisk0 – 2000 GB / 1863 GiB – 3907029168 sectors (RO), sector size=512
Disk /dev/rdisk1 – 1000 GB / 931 GiB – 1953525168 sectors (RO), sector size=512
Disk /dev/rdisk2 – 1000 GB / 931 GiB – 1953525168 sectors (RO), sector size=512
Disk /dev/rdisk3 – 640 GB / 596 GiB – 1250263728 sectors (RO), sector size=512
Disk /dev/rdisk4 – 2000 GB / 1863 GiB – 3907050332 sectors, sector size=512
My partition and Analyse results:
Partition table type (auto): Mac
Disk /dev/rdisk4 – 2000 GB / 1863 GiB
Partition table type: Mac
Analyse Disk /dev/rdisk4 – 2000 GB / 1863 GiB – 3907050332 sectors
HFS+ magic value at 512/0/1
Current partition structure:
1 P partition_map 1 511 511
2 P HFS 512 3907039743 3907039232
3 P Free 3907039744 3907040129 386
This next step is where I’m getting confused. Do I need to do it? Do I have the partition information needed to fix it already? Or do I have to go through the search? In any case, I’ve started the ‘Quick Search’ and it’s been running for almost 48 hours. It’s finding all sorts of Input/output errors. I’m not sure If I should keep scanning or if there is a faster way to get this drive (or data) back. Is this scan going to go through 3 Billion+ sectors until it finds what it’s looking for?
search_part()
Disk /dev/rdisk4 – 2000 GB / 1863 GiB – 3907050332 sectors
file_pread(13,16,buffer,510(510/0/1)) read err: Input/output error
file_pread(13,16,buffer,513(513/0/1)) read err: Input/output error
file_pread(13,1,buffer,513(513/0/1)) read err: Input/output error
file_pread(13,16,buffer,518(518/0/1)) read err: Input/output error
file_pread(13,1,buffer,519(519/0/1)) read err: Input/output error
file_pread(13,16,buffer,511(511/0/1)) read err: Input/output error
file_pread(13,1,buffer,513(513/0/1)) read err: Input/output error
file_pread(13,16,buffer,519(519/0/1)) read err: Input/output error
file_pread(13,1,buffer,519(519/0/1)) read err: Input/output error
file_pread(13,16,buffer,512(512/0/1)) read err: Input/output error
file_pread(13,1,buffer,513(513/0/1)) read err: Input/output error
file_pread(13,16,buffer,514(514/0/1)) read err: Input/output error
file_pread(13,1,buffer,515(515/0/1)) read err: Input/output error
file_pread(13,4,buffer,516(516/0/1)) read err: Input/output error
file_pread(13,16,buffer,5176(5176/0/1)) read err: Input/output error
file_pread(13,8,buffer,11191(11191/0/1)) read err: Input/output error
file_pread(13,8,buffer,11241(11241/0/1)) read err: Input/output error
file_pread(13,2,buffer,13160(13160/0/1)) read err: Input/output error
file_pread(13,5,buffer,11131(11131/0/1)) read err: Input/output error
file_pread(13,3,buffer,11136(11136/0/1)) read err: Input/output error
file_pread(13,8,buffer,11199(11199/0/1)) read err: Input/output error
file_pread(13,8,buffer,11249(11249/0/1)) read err: Input/output error
file_pread(13,16,buffer,11139(11139/0/1)) read err: Input/output error
file_pread(13,1,buffer,11139(11139/0/1)) read err: Input/output error
file_pread(13,4,buffer,11140(11140/0/1)) read err: Input/output error
file_pread(13,3,buffer,11144(11144/0/1)) read err: Input/output error
file_pread(13,8,buffer,11207(11207/0/1)) read err: Input/output error
Any help or advice would be greatly appreciated. I’m at a loss as to what I should do??!?! Thanks!!!! 🙂
–cy
Hello Perro!
I’ve been trying to accomplish your guide in order to save an external drive that suddenly isn’t mounting, it appears in Disk Utility but only the drive name itself and not the (only) partition he has, HFS+. I’ve cycled through all the comments and found one similar to my problem but there was no answer. I keep getting Floating Point Exception after typing my Password, required to run sudo pdisk /dev/rdisk6 (rdisk6 in my particular case).
Also couldn’t get any help in Google.
Any help?
Thanks!
Thank you! This worked awesome for me, even restored some partitions that I had deleted a while back! Thanks again
My friend, thank you for your advices, is very help full to me. i preciated that.
You just helped me restore 1.5TB of data. Thank you very much
Hey do you think you can help me restore mine?
Wong.Will@Hotmail.Com, please!!!
Great page here! Like many, though, I’ve run into a block because pdisk isn’t that well documented for all situations.
I’m desperate because mistakenly erased a couple of HFS+ drives in Leopard 10.5, and I worry about making things worse by selecting the wrong pdisk options.
Like others, after sudo pdisk /dev/rdisk1, I enter c (lower case), and get:
The map is not writable:
FIrst block:
If I enter “i” I get:
map already exists
do you want to reinit? [n/y]:
Testdisk sees the sectors for the drive and data,
Basically, I’m looking for some more detailed documentation and tutorial stuff on pdisk. Any pointers would be appreciated.
Heyy, Thanks for it.. my system is working back..
But Now, there is one more problem..
When I’m going to install Windows 8 on bootcamp partition its giving me all SSD is unallocated space.. you can check it from link
http://imageshack.com/a/img838/7795/frxt.jpg
The Mac OS on Disk 0 is opening, but when I reboot to install windows, there is no seperated spaces, also Mac OS partition, its united..
What can I do now?
Sorry, I forgot – “The map is not writable:” happens when the disk is still mounted.
I unmounted and eventually figured out the following from a few interenet searches and held-breath experiments.
“print the partition table”
– gives me data without destroying anything.
do you want to reinit? [n/y]:
– does not change the data
I finally had the data that our host describes.
I followed the rest of the instrructions.
Unfortunately, while the partition shows up, as it already did before, none of the files are there.
So, as far as revovering the lost data, this didn’t really help.
Oh well, but I hope my experience helps anyone else struggling wth this.
Can anyone please help me recover my erased partition! Please!!!!
Wong.Will@Hotmail.Com, ASAP thank you!!
I ran both the quick scan and the more extensive scan on /dev/rdisk1
I get – 1000GB / 931GiB 244190646 sectors
but it keeps saying, “no partitions found or selected for recovery.” any thoughts?
I ran the scan again on /dev/disk1 – 1000GB / 931 GiB – 244190646
and once again underneath Partitition, Start, End, and size in sectors…it was blank.
the scan took roughly 18 hours.
now at the bottom it says:
Keys A: add partition, L: load backup, Enter: to continue
what is my next step?
Be careful with pdisk utility!
“pdisk is for the Mac PowerPC partition table, not for the Mac Intel partition table”
Taken out from the bottom of this page here: http://www.cgsecurity.org/wiki/OS_Notes#Mac_OS_X_.28Intel.29
Current version of TD says it detects an EFI format and gives me:
Disk /dev/rdisk3 – 4000 GB / 3726 GiB – 3519069872 sectors
Partition Start End Size in sectors
>P EFI System 40 409639 409600 [EFI]
P Mac HFS 409640 7813774983 7813365344
and pdisk doesn’t seem happy once I enter any combination of these. Advice?
iMac 10.6.8 Core 2 Due
repairing an external firewire drive (4 TB) with a single partition.
perhaps this cannot handle 4 TB disks?
This can’t be solved using pdisk, because your current partitioning table is GPT because it has the EFI partition and it starts from block 40, while pdisk creates an APM partitioning table which ends at block 64.
But this is an external disk, so you can plug it to your mac and do almost the same steps using gdisk instead of pdisk (you just need to check the the proper commands)
Ran testdisk on a 2TB drive that had two HFS+ partitions on it, and it only showed one big one.
As mentioned before, I used my Mac OS X Disk Utility to erase the drive.
I started a Deeper Search, but I don’t think that works on a HFS+ setup. The results so far don’t look helpful.
I used a commercial recovery program to find and copy files from the single-partition drives, but I’m uncertain about how that will work when the two partitions don’t show up via testdisk.
Finding answers to this type of problem is depressingly difficult.
To avoid the “can’t open file for writing… resource busy”, you have to unmount the volume from Disk Utility after being entered in the pdisk utility but before issuing the “i” command.
However, I did some tests on an Intel iMac with a 80Gb disk that I formatted as GUID HFS Journaled with Disk Utility and left the disk empty with no data.
I then ran the pdisk tool and did what’s explained above by Perr0.
Although it works and seems to be recognized by the Mac, the partition map scheme seen in Disk Utility is then an “Apple Partition map” instead of a “GUID partition table”.
Even if that worked for Perr0, I’m not sure if pdisk is meant for Intel Mac
Hello, Perro.
I don’t know, how to thank you for this information.
The only problem was, I didn’t know, how to navigate trough folders in terminal, then I found this:
http://forums.macrumors.com/showthread.php?t=710382
In Terminal, if you
ls /Volumes
you’ll see all of your drives. You can then cd to one of them (or just cd directly – no need to list the volumes first). For example:
cd /Volumes/My\ Other\ Drive
Spaces are replaced by ‘\ ‘. Or you can put the whole thing in quotes:
cd /Volumes/”My Other Drive”
If the drive name has no spaces, then you’d just use the name:
cd /Volumes/MyOtherDrive
Great information! I will buy you a beer 🙂
Perro, I can’t send you the beer, since I get the following Paypal error message, when I press the “Donate” button:
Error Detected
Error Message
We were unable to decrypt the certificate id.
We were unable to decrypt the certificate id.
What should I do?
Fixed 🙂
Listen…. THANKS! Oh snap… You made my day with this tutorial. Bless you! I wish you the best man. All of my data is back now. Thanks again!
ps. I have done it on Late 2008 Macbook Alu with OS X 10.9.
Thank you so much! I have added your solution to the apple discussion forums (at least on my question) when all the pros told me that I would have to reformat and reinstall everything…. I wanted to increase the size of my boot camp partition. Paragon’s Bootcamp resizing utility failed. So I was dumb and thought “I’ll just get into disk management on the windows side, and reclaim free space made from osx partition to my Bootcamp partition. FAIL. So your solution basically made my retina mbp bootable again; only two differences. My recovery drive is now displayed, and my Bootcamp partition has disappeared from disk utility however, it still is using the space…leading me to believe the partition map for the Bootcamp partition is shot. I’m still trying to figure out what to do there, but you saved me from the hardest and most time consuming part by not having to reinstall osx! So thank you very much sir!! 🙂 🙂
Hi, I’m new bee in this, I removed my partition map by mistake.
Also I’m try terminal command to locate TestDisk but i can’t. (Its on download Only)
Please help
shahaed
Shahaed,
Try this. All the following that are preceded by a “>” are intended to be typed, with typing the “>” at the command prompt that may look like that, or could be a “$”. On my terminal, the command prompt starts with machine name, and looks like
“machine-name:~ username$
The first thing is what you call your machine, if you named it. It may have a default name, I never pay attention to those.
The “:” is followed by a “~” (tilde) which indicates that you are in your home directory.
Your username is what the folder is named that you go to when you select “Home” from the Go menu in the finder.
Seems redundant, I know.
Rather than guess at yours, I precede the parts to type with “>” The rest is narrative/direction.
First. start the terminal by double clicking it in the Applications folder, or if you have dragged it to the Dock for easy access, click it once.
Next, you want to look at your “Home” directory, so type:
> cd
You will likely see no change, as it should boot up with your home directory as the working directory.
Next, type:
> ls -la
All lower case: LS space hyphen LA.
This will list all the files and folders in your home directory. Try this for a shorter list:
> ls -l
that is LS space hyphen L
The “a” is the message to the OS to show you All the files, without that it leaves some out. Which is fine for our purposes.
Examine this list. It is probably sorted alphabetically, so Downloads is near the top.
You can type:
> cd Downloads
and then the list command again to see the volumes/disks your machine recognizes.
TIP: Type cd Dow and, if there is no other folder/directory that begins “Dow” (and capitalized/not capitalized are enough difference) then it will complete the name for you. Hit and you will be in your downloads directory.
Type the list command:
>ls -l
And you will see the files there, including, I think, the one you are looking for.
HTH
PS. Also included in the list in any directory you list are two items, named “.” and “..” These are referring to the current folder/directory, and the one immediately “above” the current one in the disk hierarchy. To quickly go up one level type:
>cd ..
Have fun!
Man, you are a Genioussssss !!!!! Saved my Neck !!!! Thank you !!!! I am donating of course !!!!!
Donations button is fixed now 🙂
Many thanks to Fam. Just rescued a disk coming out of a malfunctioning LaCie Big Disk mirror.
Partition table was gone and already replaced by an APT table.
TestDisk found the original partition.
iPartition was able to change the partition scheme back to GUID.
gpt was able to destroy and recreate the correct partition table using Fam’s instructions.
#happy
Hi
I’m not able to fix this.
From Pdisk
Disk /dev/rdisk1 -1500 GB / 1397 Gib – 2930277168 sectors
Partition Start End Size in sectors
P DOS_FAT_32 40 409639 409600 [EFI ]
P HFS 409640 2930014983 2929605344
Now how can i fix this.
Can anyone please guide me step by step.
Thanks
Shahaed
please reply
You mean from testdisk, not from pdisk, right?
anyways, this can’t be solved using pdisk, because your current partitioning table is GPT because it has the EFI partition and it starts from block 40, while pdisk creates an APM partitioning table which ends at block 64.
But if this is an external disk, you can plug it on your mac and do almost the same steps using gdisk instead of pdisk (you just need to check the the proper commands)
After much trouble along the lines of many here because my disk uses GPT and not APM I downloaded the gdisk utility (this is a utility that uses fdisk commands – there is no gdisk command). HERE’S the download link: http://sourceforge.net/projects/gptfdisk/
Install it.
Open terminal, type “sudo gdisk” and it will run.
GPT fdisk (gdisk) version 1.0.0
Type device filename, or press to exit:
Use the disk name found in testdisk
Mine said it found a valid GPT but with corrupt MBR.
I typed “w” to write the new partition and rebooted my computer.
My whole drive came up with all it’s partitions in tact. Voila!
Good luck folks!
Please someone update this for us not terminal users … Maybe a youtube video ?
Graid 3 2TB
MBP 2010 Intel
(running OSX & Parallels + WIN XP)
Parallels was definitely the problem here !! Ok we finally got it to work. Some of your instructions aren’t clear after step 7 or 8, but we got it. We used the instructions from CGsecurity.org as well.
http://www.cgsecurity.org/wiki/OS_Notes#Mac_OS_X_.28Intel.29
Notes for non terminal guys like us
Step 2 – Drag the testdisk-6.14 to your desktop or folder (we named our folder testdisk-6.14. To locate that file in the terminal type
cd ./Desktop/testdisk-6.14
Next type
ls (that’s a lower case “L”)
Step 10 – no need to copy & paste or handwrite the info in from the testdisk-6.14 analyze test. Just hit enter twice and the screen shot should look just like Perro’s step 9-10 pic.
sudo pdisk /dev/rdisk1
Password:
pdisk: No valid block 1 on ‘/dev/rdisk1’
Edit /dev/rdisk1 –
Command (? for help): c
No partition map exists
Command (? for help): i
A physical block is 512 bytes:
A logical block is 512 bytes:
size of ‘device’ is 3907050332 blocks (512 byte blocks):
new size of ‘device’ is 3907050332 blocks (512 byte blocks)
Command (? for help): c
First block: 262208
Length in blocks: 3906788120
Name of partition: Graid3
Command (? for help): w
Writing the map destroys what was there before. Is that okay? [n/y]: y
The partition table has been altered!
Command (? for help): q
********-MacBook-Pro:testdisk-6.14 ********
For privacy reasons the ***** are deleted names.
Thank you so much for posting this and want to reward you for your great efforts !! Please email me when you get a free moment, we have a gift for you !!!!!
New Video Compares Look Of Iphone Five 5S And 5C | Simple Computer Solution
Computer Problems And Solutions | Simple Computer Solution
Apple Pc Mac Restore Hk How To Partition And Format A Drive In Os X | Quick Mac Services
AWSOME!!
I had a 2 TB WD passport that I accidentally deleted the partition of, and this saved my day!!
I had to alter the sector size though when hitting the “i” to 4096 since it’s a 2 TB device. So I changed the physical size and the logical size to 4096, and then everything worked like a charm (I didn’t get the map is to big -error) 🙂
OMG – Awesome stuff! Worked perfectly!
I screwed up the first time on step 11.(i.e.Now if you are completely sure you wrote down everything correctly ….), keyd in wrong values…it obviously didnt work the first time, and it also didnt work the second time with the correct values :((
Did I just flush my data down the drain for good??
It sounds like I had the exact same issue as your example case – preparing to partition SSD in my new fancy schmancy MBP partitioned a little bit of the external disk (with, essentially, my whole life on it) for the wininstall partition, and then it overwrote the partition table for the entire disk when I was foolishly trusting it to only use the portion I had set aside. Oops.
Like your example, I immediately unplugged it all, and started looking for solutions. Google+ yielded the link to this page (thanks Matt R.) and I exulted in what appears to be the solution to my problem.
Unfortunately, I get to the enter start block, enter size, enter volume name and the response to my Volume name is “Bad Size.”
So, I thought perhaps if I put my volume name (two words) in quotes, that might help.
New response: requested base and length is not within an existing free partition.
So, I feel like I am very close to avoiding my appointment at the local Genius Bar by fixing this myself and so being able to cancel, but I am not quite there, and I kind of expect that my affable neighborhood genius is kind of likely to completely fubar this.
Any ideas?
When I type “p” in pdisk, I get this encouraging message:
“Partition map (with 512 byte blocks) on ‘/dev/disk2’
#: type name length base ( size )
1: Apple_partition_map Apple 63 @ 1
2: Apple_Free Extra 19535291 @ 64 ( 9.3G)
3: Apple_HFS Crime 1933989808 @ 19535355 (922.2G)
4: Apple_Free Extra 5 @ 1953525163
Device block size=512, Number of Blocks=1953525168 (931.5G)
DeviceType=0x0, DeviceId=0x0
”
I tried just entering the volume name as “Crime” to no avail. New response from above was repeated.
Anyone here have any ideas?
If you are talking about your MBP hard disk, then I think you and I have the same problem. The problem is that new MBP are partitioned using GPT “GUID partitioning tables”, which takes 40 blocks then most probably have an EFI partition (around 200MB) that starts from block 40.
But The pdsik program partition your disk to be APM “Apple partition Map” which takes 63 blocks, so if you are trying to put your first partition (EFI, the 200 MB, from block 40 to say 409600, that was in my case), it will always give you this error: requested base and length is not within an existing free partition.)
so what you have to do is get past this first partition and just put the next ones. The good thing is MBP can boot from APM partitioning tables, and your OSx will boot normally. But if you happened to have a bootcamp (Windows, like in my case) or want to have it in the future, you won’t be able to, because it’s supported on the GPT tables with a hybrid MBR tables. But if you are fine using
I would like to get my bootcamp back, but so far, I can’t find a way to convert APM to GPT, so I might have to copy my data, format my whole drive and repartition it. But in your case, if you are fine with only your OSx, then you should just skip the first partition as I said and you should be good to go.
Hope this helps. 🙂
Hi,
it worked, you saved my entire photo collection 😀 thanks a lot!
PS, the donate option doesn’t work..(We were unable to decrypt the certificate id.)
Regards,
Alex
I’ve fixed the donations button 🙂
That is great. This week I start work, and will gladly donate once I get my music library back. So far I have not been able to get this to work for me, which seems odd, since I did the exact same thing your friend did, and I have followed the instruction exactly.
OMG you’re a lifesaver!
I had two external drives connected and was about to backup my photos from the last couple of months. I meant to change the partition structure on the backup drive (it was previously used for something else) and accidentally deleted the partition table on the drive with the photos!!
Testdisk has improved since your article and I didn’t have to use pdisk. Basically once I found the partition I just told it to write the changes. Testdisk isn’t super clear if you haven’t used it before, I was expecting the deleted partition to show up as D for deleted but it was displayed as P for primary but the website documentation is okay if you take your time and read it slowly.
Thanks you very much for this post PerroHunter,you are a hero without cape !! I have a simple question: On step 8: My SATA drive was restored from and EMPTY drive( as HHD upgrade gone wrong) has been now formatted as Extended Journaled, with the installation of the MAC Os High Sierra which now shows 2 new partitions ( Recovery HHD and NameHHD).
I did a DeepSearch of the current drive as it is, and after waiting patiently ,I now have a LONG list of information with Partitions info , size, etc. ( something like “Juan May 31, 2014 at 4:31 pm”
What should be my next step?
Thanks again for your contribution !!
I just dded over my external HDD, and found this promising guide. Can you please put up a Dogecoin wallet address to donate to in case this works out? Thanks!! You can read about dogecoin in the link I entered. I am 100% serious by the way!
After following carefully these directions, I keep getting bad size, bad name and requested base and length is not within an existing free partition error messages.
What am I missing or doing wrong?
I’m not familiar with using Terminal commands. How did you search for the unzipped Test-disk? When i enter ‘sudo ./testdisk’ into the Terminal it says:
toms-mbp:~ walkertom$ sudo ./testdisk
Password:
sudo: ./testdisk: command not found
toms-mbp:~ walkertom$
Any help would be greatly appreciated!
Cheers, Tom
e.g. if your unzipped testdisk folder is in your downloads folder, type:
cd ~/downloads/your-unzipped-folder
(~ is short for your home directory)
and then execute the sudo command.
I hope this helps
big up
type ‘ls’ to list the data in that folder to make shure you are
you just made my day!
big up, wax
You’re my hero! Thanks a lot.
Cheers.
Got the same problem, a 1.5Tb drive that lost the partition map. Went crazy at first, and then found your post. While your solution didn’t help me, it pointed me to Drew’s post, and that really saved my day!
Thanks to all!
Hola Podrias ayudarme, me sale lo siguiente después de hacer lo que mencionas con TestDisk
andres-pc:testdisk-6.14 andres$ sudo pdisk /dev/rdisk2
Password:
pdisk: No valid block 1 on ‘/dev/rdisk2’
Edit /dev/rdisk2 –
Command (? for help): c
No partition map exists
Command (? for help): i
pdisk: can’t open file ‘/dev/rdisk2’ for writing (Resource busy)
This is amazing!!!…my HD was not reading…left for over 4 months…decided to look into it today and found your post…you are a life saver!…thanks so much man!… 😀
I also received this message:
pdisk: can’t open file ‘/dev/rdisk2′ for writing (Resource busy)
And I cannot continue from there.
I had the same problem, I solved it by running:
diskutil unmountdisk /dev/diskN
Hope this helps!
Heyy, Thanks for it.. my system is working back..
But Now, there is one more problem acquired..
When I’m going to install Windows 9 on bootcamp partition its giving me all SSD is unallocated space.. you can check it from link
http://imageshack.com/a/img838/7795/frxt.jpg
The Mac OS on Disk 0 is working as normal as before, but when I reboot to install windows, there is no separated spaces, also Mac OS partition, its all united..
What can I do now?
hi
power failer make my life nightmare it damage my hackintosh driver
i try to follow you but with no luck
my story i have 1 TB hdd first i was partition it to two partition but after i mange to merge the two partition to one partition and everything work fine until that day when power fail tow time it fuck my hdd
any way i get hopeless and repartition it and install new os but i need my data back not all data only name of folders was in my document
Thanks Man!!! you just saved a life
“13. You are a hero, no matter if it’s your own disk, you just saved your data!”
No, man… YOU ARE.
If you are using a regular pitch, then place the tea in a T-sac
first to make it easier to strain your tea, especially if you
are using some kind of herbal tea. People who make a point to
consume foods that contain RGCG keep themselves detoxified.
Water has miraculous effect in weight reduction by consuming extra calories
and detoxifying body.
LIFESAVER!! THANK YOU!!!!!!! poor student else i would definitely donate.
EVERYONE LOOK HERE if you have a 2TB external Drive. If you have a hard drive over 1TB, it’s most likely have been formatted in HFS+. It most likely has a sector size of 4096.
Therefore, you have to change the geometry of the drive.
1. Choose [Mac] or [EFI-GPT] (doesn’t matter).
2. Choose [Geometry]
– Change [Heads] to 255, [Sectors] to 63, and [Sector Size] to 4096
3. [Analyze], and find your Start sector, and size (remember to mentally plus 1 to the number under “END”, for example:
START END SIZE IN SECTORS
32776 488370429 488337654
Now, on another terminal window:
sudo pdisk /dev/rdisk(x)
You should see something similar to below (map already exists may not show up). Change physical block, logical block to 4096. Just press ‘ENTER’ for “size of 0 blocks (4096 byte blocks), then for the next prompt, “what should be the size:” enter whatever the number was under the “END” + 1 (so, in this example, it’s 488370429 + 1 = 488370430):
Command (? for help): i
map already exists
do you want to reinit? [n/y]: y
A physical block is 512 bytes: 4096
A logical block is 512 bytes: 4096
size of ‘device’ is 0 blocks (4096 byte blocks):
what should be the size? 488370430
new size of ‘device’ is 488370430 blocks (4096 byte blocks)
Next, press lowercase ‘c’, and enter the first block, and the length in size (START, and SIZE IN SECTORS numbers respectively from TestDisk):
press ‘w’ and you’re done.
Complete pdisk prompt below (replace x with what your disk number is):
$ sudo pdisk /dev/rdisk(x)
Command (? for help): i
map already exists
do you want to reinit? [n/y]: y
A physical block is 4096 bytes:
A logical block is 4096 bytes:
size of ‘device’ is 488370430 blocks (4096 byte blocks):
new size of ‘device’ is 488370430 blocks (4096 byte blocks)
Command (? for help): c
First block: 32776
Length in blocks: 488337654
Name of partition: Passport
Command (? for help): w
Writing the map destroys what was there before. Is that okay? [n/y]: y
The partition table has been altered!
OMG …. AWESOME …. IT WAS SUPER AWESOME …. I JUST GOT MY HDD TO WORK AFTER TWO YEARS …… ALL THE THANKS TO YOU MY BUDDY … MAY YOU LIVE THOUSAND MORE YEARS
THANK YOU!!!!
I tried to read some files on my PC from a 500gb External WD formatted from a 2008 Mac. In trying to get the PC to read the disk, I accidentally initialized the drive on the PC thus rewriting the partition. It showed no files whatsoever neither on my PC or my Mac.
I followed this tutorial as well as one found at
http://nathanhein.com/2011/12/osx-hard-drive-recovery/#comment-1532
That tutorial was a little clearer on the pdisk portion.
On step 8 (after entering pdisk and submitting my password) entering “c” yielded nothing for me. Though on step 9 (after entering “I”) I received,
map already exists
do you want to reinit? [n/y]:
I double checked that I had chosen and written the correct drive (in my case it was dev/rdisk1) and selected “Y”.
After entering “Y”, the rest of the steps are exactly the same.
After step 21, it will show a warning that writing the map destroys what was there before. I selected “Y” and after writing “quit” on test disk my drive popped up on the desktop!
I followed the this tutorial for the testdisk portion and the nathanhein.com tutorial for the rest. This was pretty straight forward and saved my drive!!!!!!
Thank you for this helpful post.
Note to others: in my case it worked when I selected /dev/rdisk1.
Thanks. Worked like a charm!
I’m still a bit confused about what goes with Apple Partition Map vs GUID and a few other things.
We have a 1TB HGST HTS721010A9E630 laptop drive, that was accidentally “Partitioned” used 10.9 Disk Utility with a single HFS+ partition. It used to have more than one HFS+ partition.
http://www.hgst.com/hard-drives/mobile-drives/9.5mm-mobile-hard-drives/travelstar-7k1000
Daniel suggests changing the Geometry settings for larger drives. The datasheet says this drive is an Advanced Format drive with 4,096 byte sectors. So that is what we want for the Sector Size, but I don’t see where one gets the number of heads or sectors. His example is 255 for Heads, but does any drive really have that many heads?
Mazen suggests using gdisk instead of pdisk for GPT disks, which I would think this would be. But more people seem to be reporting success with pdisk, then one would expect given how long Intel Macs have been out. Does this matter?
Lastly, when I run TestDisk, I don’t just get four partitions like Perro and some of the others show, I get quite a few more. This drive may have had some .dmg disk images on it, is that the cause, or are these likely real partitions?
And how do I tell the new partition accidentally put on by Disk Utility from the ones we want to recover?
I a new for Mac.
Problem:
3.- I issued the command ‘sudo ./testdisk’ it indetially promped me to make my terminal bigger
How I can use this command (what key I have to press etc.)
Just make the terminal window a little bigger
My brother suggested I might like this website. He was totally right.
This post actually made my day. You cann’t imagine simply how
much time I had spent for this info! Thanks!
Also visit my site – adobe [http://www.adobe.com/]
Amazing. Thanks for this guide. I followed your instructions, but got the ‘map not big enough’ error, on a 2TB drive with a single HFS+ partition.
Then, after two days of puzzling, I realised that testdisk was detecting/hinting that it was a Mac (Apple partition map) partition. But a recent drive of that size should use the testdisk EFI GPT partition table type. So…I restarted testdisk, selected EFI GPT, found the partition, and testdisk wrote the new partition map for me and told me to reboot… It worked! 1.8TB of files and folders back online! And no need to use pdisk etc.
I couldn’t have done it without this guide to point me in the right direction. Thank you!
I went through something similar and was able to fix it by doing the following (first thought it was Apple partition map then realized it was EFI GPT). I fixed my problem in a slightly different way though. I just used the following commands:
sudo gpt recover /dev/rdisk2
diskutil repairDisk /dev/disk2
(Used “disk” and not “rdisk” with diskutil as the “r version” didn’t show up when running “diskutil list”)
In the end, neither testdisk and pdisk were not utilized in actually fixing the problem.
Excellent post. I was checking continuously this
blog and I’m impressed! Extremely useful info specifically the last part
🙂 I care for such info a lot. I was looking for this certain info for a long time.
Thank you and good luck.
Feel free to visit my blog: birthday party places for kids
Hey Perro, I’m pretty sure my partition table is effed. I tried your method, but pdisk tells me that “the map is not big enough.” I entered in all the data TestDisk gave me…
Any ideas?
What’s the device maker? I’ve seen this issue specially with some vendors that make the block size bigger
Hello,
I’m also stuck with
pdisk: can’t open file ‘/dev/disk5’ for writing (Resource busy)
has anybody managed to get around this? testdisk seems to discourage using pdisk in a not PowerPC environment.
make sure to unmount the drive in Disk Utility
Hi there,
I had already tried to do that, but every time I try to do so, I get the annoying spinning bach ball. Isn’t pdisk only meant to work under PowerPC?
thanks for your response!!! 🙂
I’ve posted more information here:
https://discussions.apple.com/thread/6242431
thanks PERR0_HUNTER
PS: How funny to see spanish words on the snapshots!! 🙂
Hi Marc,
If you can’t unmount the drive means something else is using it, I see on your Apple post that you have a NAS solution, perhaps that’s using the resource and not letting you unmount the drive. pdisk should work under powerPC aswell as it’s an apple tool 🙂
Well, at first I thought that my disk was toast and decided I would get a new disk from Amazon.
After I got the new disk, I hooked the damaged disk up to my NAS, and to my deep surprise, it mounted just fine, and the data can be accessed with several limitations. Specifically, the data on the damaged disk is Time Machine backups, and, unfortunately, I can’t get those backups over to the new disk (attached to my Mac OS X) because the NAS published the data over AFP which isn’t friends with symbolic and circular links and other stuff to be found on Time Machine backups… Just to be clear, I connected the disk to my NAS just to discover a linux was able to mount the disk. All the steps I report here or on the Apple site are issued on the damaged disk connected back-to-back to my Mac mini.
I’ve just updated the post on the Apple site with more details.
Thanks
An you are the Hero – that for sure !
On advice to all owner of an external USB drive with Apple Partition Table:
Don’t plug the device, under what ever circumstances, in to a Android TV Box!
It looks like Android 4.x identifies the device as empty and format it with a nice FAT Partition including DOS partition-table.
Hi Perro,
I did as you adviced but the result from testdisk is very messy. So I do not know what is next step. Could you please help me. This HDD has all my data. Thank you very much.
Disk /dev/rdisk1 – 500 GB / 465 GiB – 976711728 sectors
Partition Start End Size in sectors
> Mac HFS 974201231 975470766 1269536
Mac HFS 974201296 975470831 1269536
Mac HFS 974201393 975470928 1269536
Mac HFS 974201458 975470993 1269536
Mac HFS 974201555 975471090 1269536
Mac HFS 974201620 975471155 1269536
Mac HFS 974201717 975471252 1269536
Mac HFS 974201782 975471317 1269536
Mac HFS 974201855 975471390 1269536
Mac HFS 974201920 975471455 1269536
Mac HFS 974202017 975471552 1269536
Mac HFS 974202082 975471617 1269536
Mac HFS 974202179 975471714 1269536
Mac HFS 974202244 975471779 1269536
Mac HFS 974202341 975471876 1269536
Mac HFS 974202406 975471941 1269536
Mac HFS 974202503 975472038 1269536
Mac HFS 974202568 975472103 1269536
Mac HFS 974202665 975472200 1269536
Mac HFS 974202730 975472265 1269536
Mac HFS 974202859 975472394 1269536
Mac HFS 974202924 975472459 1269536
Mac HFS 974202979 975472514 1269536
Mac HFS 974203052 975472587 1269536
Mac HFS 974203117 975472652 1269536
Mac HFS 974203214 975472749 1269536
Mac HFS 974203279 975472814 1269536
Mac HFS 974203376 975472911 1269536
Mac HFS 974203441 975472976 1269536
Mac HFS 974203538 975473073 1269536
Mac HFS 974203603 975473138 1269536
Mac HFS 974203700 975473235 1269536
Mac HFS 974203765 975473300 1269536
Mac HFS 974203838 975473373 1269536
Mac HFS 974203903 975473438 1269536
Mac HFS 974203968 975473503 1269536
Mac HFS 974204033 975473568 1269536
….
Hi Perro,
I did as you adviced but the result from testdisk is very messy. So I do not know what is next step. Could you please help me. This HDD has all my data. Thank you very much.
Disk /dev/rdisk1 – 500 GB / 465 GiB – 976711728 sectors
Partition Start End Size in sectors
> Mac HFS 974201231 975470766 1269536
Mac HFS 974201296 975470831 1269536
Mac HFS 974201393 975470928 1269536
Mac HFS 974201458 975470993 1269536
Mac HFS 974201555 975471090 1269536
Mac HFS 974201620 975471155 1269536
Mac HFS 974201717 975471252 1269536
Mac HFS 974201782 975471317 1269536
Mac HFS 974201855 975471390 1269536
Mac HFS 974201920 975471455 1269536
Mac HFS 974202017 975471552 1269536
Mac HFS 974202082 975471617 1269536
Mac HFS 974202179 975471714 1269536
Mac HFS 974202244 975471779 1269536
Mac HFS 974202341 975471876 1269536
Mac HFS 974202406 975471941 1269536
Mac HFS 974202503 975472038 1269536
Mac HFS 974202568 975472103 1269536
Mac HFS 974202665 975472200 1269536
… etc
Warriors top rate & fashion origional design for our kind customers with no tax.
Tried both test disk & disk warrior and DW seems to be a better option than test Disk but too costly. Then tried Stellar Volume Repair which was half the price of Disk Warrior and rebuilds Mac OS X partition. Hence, this tool is cheaper than its competitor and achieves high on results. Also, this is a fine alternative for Disk Utility http://www.stellarinfo.com/blog/the-efficiency-of-stellar-volume-repair-in-comparison-to-disk-utility/
Awesome! Amazing!
It’s been six months I’m looking how to fix my disk, thank you
Excellent site. A lot of useful info here. I’m sending it to a few pals ans also
sharing in delicious. And naturally, thanks on your effort!
HELP!!
After several “analyse” that only revealed my “P Mac HFS” partition (when I ran EFI GPT option) out the 3 that I originally had, I tried to analyse with the unformatted option selected. Then I got this message.
Disk /dev/rdisk1 – 2000 GB / 1863 GiB – 3907029168 sectors
The harddisk (2000 GB / 1863 GiB) seems too small! ( VMFS 1445456508 30328706640183218 30328705194726710
My 3 partitions were formatted originally as:
ex-fat and mac journaled I think. Is there anything else I can do or did I lose everything??
Hi Chatzi,
Did you create a new partition table with just 1 table on your disk before attempting this? Like formatting?
No, I didn’t do anything like that, or at least not intentionally!
If you mean, before the breakdown of the hard drive, no. It was working properly, until one day my computer could not find it when I plugged it in.
The harddisk (2000 GB / 1863 GiB) seems too small! ( VMFS 1445456508 30328706640183218 30328705194726710
Sorry, I missed to post the whole message! Thanks in advance!
The following partitions can’t be recovered:
Partition Start End Size in sectors
SysV 4 874389474 47499447681 46625058208 [~v^?x ]
> VMFS 1445456508 30328706640183218 30328705194726710
Hi, thanks for the tutorial! I have but one issue. When I enter the command pdisk /dev/rdisk1 on step 8, I get a floating point exception. I don’t see this covered in your tutorial, and I wanted to know if you had any knowledge on resolving this issue. Thank you.
Hi, I’m kind of desperate here since I accidentally erased the partition on Disk Utility while trying to erase another disk, and it was replaced with a new partition.
To make things worse this macbook is from a client, and I’m really worried about it.
I followed all your instructions, but the only partition I get to work is the new one, which have overwritten the original, so the files are not there.
I also got a lot partitions with close “start values” from the new partition in testdisk (all with the same size in sectors), but I tried all of them (about 15) and all of them renders an unreadable disk from Mac OS X.
Do you have any idea on how could I get my old partition to be read instead of the one that replaced it?
Thank you,
Cassio
Data recovery on a MAC HFS journalled external drive | Ben Powell
I followed the instructions and it didn’t work for me, so I think I’m missing something. If anyone feels that they have this down please let me know. I’d be willing to pay someone who’s really good at this to re-write my external hd disk partition. It could be done remotely with jabber screen-sharing. This is my last resort before throwing the HD in the garbage. Thanks!
Mate, you are a legend. Thanks – so, so much!
Just want to say that your instructions also saved my day, 500 GBs resurrected 😀 thx bro.
Hi! 😀 I did as you instructed and I just wanted to know if ‘Writing the map destroys what was there before. Is that okay? [n/y]” is what I should get after inputting ‘w’? Please let me know. thank you!
You should get that 🙂
Hello Perro!
Thank you for the quick reply! I followed through but it didn’t work for me. Perhaps I am doing it wrong? I am not tech savy, so I can go through the beginning steps with you?
1. I download the test disk and I click on testdisk. Then I create a new long file.
2. Then I am presented with
Select a media (use Arrow keys, then press Enter):
>Disk /dev/disk1 – 132 GB / 122 GiB
Disk /dev/disk2 – 132 GB / 122 GiB
Disk /dev/rdisk1 – 132 GB / 122 GiB
Disk /dev/rdisk2 – 132 GB / 122 GiB
how do I know which media to choose? What is the difference between the choices?
>[Proceed ] [ Sudo ] [ Quit ]
3. Do I select proceed or sudo?
P.s. Sorry for the silly questions due to little knowledge of this language.
You should sudo and proceed
Hi PERR0 HUNTER,
Thanks for the post. At step 5 when I hit Analyze, it gives me
Bad MAC partition, invalid block0 signature
and then it gives me Quick Search instead of Quick Analyze, when I click Enter, it seems is going through all the sectors of my 3TB hard drive and it never ends! I’ve been at it for hours and is still at 1%.
Is this the only way to get to next step?
Thanks a lot!
I never ever say thank you. But, you saved my life’s work, and I love you.
If some one needs to be updated with hottest
technologies after that he must be go to see this site and be up to date all the time.
Here is my blog – https://Developer.mozilla.org/en-US/profiles/rubonviolau
Hello,
My mac suddenly won’t recognize my external hard drive and tells me “the disk you inserted was not readable by this computer. [ignore] [eject]”
I haven’t gotten this to work just yet but it did give me a bit of hope that my external hard drive (WD My Passport for Mac) is still somehow alive. (Although, it says the partition’s just around 1.0GB+ when I’m pretty sure the contents are WAY more than that.
But anyway, I’ll recover what I can.
Problem is, the hard drive is password protected. Which is probably why TestDisk denies me permission and tells me “can’t open file ‘dev/rdisk2’ for writing (Permission denied).”
Anyone know how to fix this? I’d literally owe you my life. Please help me.
Hi Perro,
i have this error–>
any solution?
pdisk: can’t open file ‘/dev/rdisk0’ for writing resource busy
thanks!
Hi Ed, you can’t write to the same disk form which you are running the OS, so rdisk0 is not the right disk to use, check for the right name of the disk you want to fix.
Hi Perro,
I have tried rdisk1 too..
gotten the same result.
thanks
My problem on a Intel HDD (from a 5 years old MacBook Pro) was, that I had wrongly chosen Mac (Apple partition map) in the Partition table type selection. So I read later after analyzing:
“Function write_part_mac not implemented
Use pdisk (Mac) or parted (Linux) to recreate the missing partition
using values displayed by TestDisk”
Using pdisk is now not an option because this is only for clock-old PowerPC HDDs, not for the Intel System, which is since long the Mac System.
So just chosing:
[EFI GPT] EFI GPT partition map (Mac i386, some x86_64…)
did the trick, analyzing and writing and all data were back.
pdisk is not needed here, because TestDisk can write on the actual Intel EFI GPT partition table type.
Thank you.
frank
The easiest way to launch testdisk is to double click the unix executable in the test disk folder. 🙂
Hi,
I’ve heard such great things about this blog, and now that I’ve stuffed up my hardrive, i was glad to fins this page, however now i’ve hit another road block I’m wondering if you will help me through.
I got up to Step 4 without a hitch, and then when I went to look for something that said ‘analyse’ i instead got a menu asking me to choose a ‘partition table type’ and these were my options:
Please select the partition table type, press Enter when done.
[Intel ] Intel/PC partition
>[EFI GPT] EFI GPT partition map (Mac i386, some x86_64…)
[Humax ] Humax partition table
[Mac ] Apple partition map
[None ] Non partitioned media
[Sun ] Sun Solaris partition
[XBox ] XBox partition
[Return ] Return to disk selection
This has me confused beyond belief! The hard drive I’m using is the WD My passport for Mac, and my MacBook is running OSX 10.4.9
If you have any ideas, please feel free to email, i have some photos on this disk i’d like back!
I was a Hero too.
Thanks! And have a nice week.
thank you so much!
YESSSSS!!!!! Thanks a LOT. That’s all I can say….
Remarkable! Its in fact remarkable post, I have got much clear idea regarding from this
post.
You sir a king of kings! After my 3tb hitachi vanished, I got it back with your help, kinda, I did the pdisk bit and created the missing volume(partition) but something weird is happening, the volume reads as 3TB but the drive detects as 801GB in disk utility :/
Any thoughts?
Thank you so much, you are God… I would definitly pay you a drink if one day you come to Paris, France 🙂
You are a gernius! It worked like a charm and saved me $100 and a lot of aggravation!!!
One minor clarification. Since it is possible to have 2 or more open terminal windows at the same time, there really is no reason to write anything down. Simply keep testdisk open at the drive in question and you will see the “start” “size” and “end”.
Your way works as well but my penmanship and ability to accurately transcribe are often called into question! So with 2 windows open, all that you need to do is copy and past. At least for me it’s much safer and more accurate.
Thank you!!!
I have never written to thank someone on a website before but I just want to say a very sincere thank you!! This worked and now I will make sure I backup my data more than once ha ha!! There are still decent people out there looking to help! You’re a star!!
Repair a Mac OS X HFS+ Partition table – [PERR0_HUNTER] | Culture Foam: Bubbling Up
Help me! I get stuck after I do the quick search. This is what I get:
check_FAT: Unusual media descriptor (0xf0!=0xf8)
Warning: number of heads/cylinder mismatches 16 (FAT) != 1 (HD)
Warning: number of sectors per track mismatches 32 (FAT) != 1 (HD)
EFI System 40 409639 409600 [EFI]
I would appreciate it so much if you’d try to help me with this!
Man! I am so happy! You are my hero! After every other site was giving me no hope to get my data back I came here and did it <3 In my case Windows on Bootcamp suddenly crashed destroing in the same time my partition tables (still don't know how). Do you have any PO Box addres or sth to send a case of beer? 🙂
Thanks for this.
I was so worried but I was able to recover all the files from my external hard drive (1tb) with all the filing structure
Hi!
First off, thanks for the excellent guide!
Sadly, I’m having the same problem some other have: The TestDisk search seems to run fine, but it detects an Apple/HFS partition instead of an EFI/HFS+ combination. So if I follow your guide, I do end up with a recovered partition, but disk utility tells me its defective and needs to be erased. Checking the attributes, I see that it’s defaulted to an APM, not GUID. What do I need to do?
Thanks for your help!
Hi Perr0_Hunter,
Thanks for the guide and additional help.
Similar to above I am now stuck with an APM instead of GUID after trying to recover table/partitions. There’s a bit more to it, especially how it all started but that is too much info to list here so if you would be so kind to email me back I will explain more in detail.
Thanks in advance.
Regards,
Wim
One thing I noted that were slightly different than your directions – i was asked to select the partition table type. (efi gpt, Humax, Mac, None, etc) I chose mac (external is used on macs) though now wondering if this might be the source of my error.
Also – would be helpful to clarify which media/discs to choose from. I used a process of elimination – choosing the, and seeing if there was write access, though there were at least two accessible, of which the “none”partition was detected (alongside a note that said this was very rare and not to select it).
confusing!!
Thanks bro. You saved my entire work – better find a good cloud based app for backup.
I’m in a major bind, deleted the main partition on my drive and formatted over it. At the same time, locked out of all backups on iCloud, because I enabled 2 step recovery and it does’t work. Came across this blog and you seem like the only one with the right answer.
Please Help?
Pretty Please?
(cherry on top)
Hi! I just wanted to express my sincere gratitude for your awesome tutorial! Is there a way to determine which disk to use? I attempted disk1 using your instructions but my hard drive still wasn’t working. I guess it was maybe the wrong disk. Then I went into teskdisk again and more options came up than the initial testdisk run. I then selected rdisk1 and it seems to be taking quite a long time to even get past 0%. How long does this typically take? Should I continue to let it scan?
I’m almost there and have not yet lost hope. Please help!
hello can someone help me i have and imac with 2 partition os x yosemite and windows 8.1 i was running os x yosemite and everything was good so i go with windows to play games and when i try to go back to os x y restart and i wont start my os x partition ask me to use a backup or format the partition but i never backup my os x partition and i dont whant to format and lost my data so i start my windows partition and start running slow and check my hard drives and it show my os x partition with files so i try again to restar with os x and same so i start copying my files with windows to a hard drive but i dont want to format my drive can someone help how to recover or repair my os x partition with my windows partiiton
I’m so thankful I came across your post! Your explanation and direction were perfectly clear for someone like me who uses a mac but almost never touches the terminal. I had a 750 GB, 4-year-old Toshiba Canvio drive that recently stopped showing up in Finder (I know, shame on me for not backing it up at this point). Disk utility shows the drive but not the volume. Repair options along with most other functions were grayed out. The drive had only one HFS partition with no human error in operating it as far as I know (besides maybe not properly ejecting a couple of times). I even tried a new SATA USB adapter to check if the interface was the issue to no avail. After following your directions, TestDisk worked beautifully. Some steps did take a while to complete, but immediately afterwards, the drive showed up in its original form under Finer. I didn’t even need to unplug or restart.
Thank you so much for giving us hope of repairing our own disk without spending at least $100 on a software that may or may not work. Thank you! Thank you! Thank you!
Hi,
I have a similar problem: My RAID 1 system failed and now I have two 4TB HDDs that won’t be recognized by the system.
I followed your steps, but the pdisk sais “the map is not big enough”.
Tobias-Friedrichs-iMac:testdisk-7.0 iTobi$ sudo pdisk /dev/rdisk5
Edit /dev/rdisk5 –
Command (? for help): i
map already exists
do you want to reinit? [n/y]: y
A physical block is 512 bytes:
A logical block is 512 bytes:
size of ‘device’ is 4294967295 blocks (512 byte blocks):
new size of ‘device’ is 4294967295 blocks (512 byte blocks)
the map is not big enough
Command (? for help): c
First block: 40
Length in blocks: 409600
Name of partition: UNO
the map is not big enough
Command (? for help): c
First block: 409640
Length in blocks: 7813250992
Name of partition: DOS
the map is not big enough
Command (? for help): w
Writing the map destroys what was there before. Is that okay? [n/y]: y
The partition table has been altered!
Command (? for help): q
Tobias-Friedrichs-iMac:testdisk-7.0 iTobi$
Have I done a mistake?
It would be great if you could help.
Thanks a lot in advance
Tobias
Hi,
I’ve just ran testdisk to my deleted partition table and came up with these results:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
HFS 2048 1748719615 1748717568
HFS+ found using backup sector!, 895 GB / 833 GiB
FAT32 515094360 1712341441 1197247082
HFS 1736750696 1736776039 25344
HFS+ blocksize=4096, 12 MB / 12 MiB
HFS 1736914152 1736939279 25128
HFS+ blocksize=4096, 12 MB / 12 MiB
FAT32 LBA 1736941336 1737094935 153600 [NO NAME]
FAT32, blocksize=1024, 78 MB / 75 MiB
Linux 1737094936 1740351255 3256320
ext3 blocksize=4096 Large_file Sparse_SB Recover, 1667 MB / 1590 MiB
Linux 1740400576 1743656895 3256320
ext3 blocksize=4096 Large_file Sparse_SB Recover, 1667 MB / 1590 MiB
* HFS 1748719616 1953519615 204800000
HFS+ blocksize=4096 + Backup, 104 GB / 97 GiB
interface_write()
1 * HFS 1748719616 1953519615 204800000
write!
Can you help me filling in the blanks for pdisk so that I actually add the correct info to the partition table? I’ve tried some stuff, but it does not seem to initialise the disk. (I only had 2 partitions on this disk, both OSX HFS+ as far as I remember)
Rein
Hey Rein, looks like only the first partition on that list is enough for you
I’m trying to follow your tutorial to fix an external containing Time Machines backups. However I get the following error in Testdisk.
From what I can tell there isn’t any partition from the drive mounted.
And if I choose to continue i see this.
What are my next steps?
All the info you need is right there, ignore the EFI partition and input the data for the mac partition, start and size are there 🙂 copy with caution
I have a weird problem and it all started after I was finally able to get Windows 10 to upgrade my Windows 7 bootcamp. I had been using the paragon HFS+ tool in Win 7 and have it installed in Win10 now. Before I had it installed I tried to open up my external drive that’s formatted in HFS and accidentally incorrectly initialized it in Win10 Disk Management.
I thought I had lost everything since Win10 was showing it as entirely unallocated with no partitions on it but booted back into OSX and it all was fine there. I did use the disk utility to check the disk in OSX and it did say it needed to be repaired so I repaired it and it continued to work correctly in OSX. I thought it had been fixed but back in Win10 it still showed as unallocated, I installed the paragon HFS tool thinking that would fix it but still no go.
So as of this time it’s still working correctly in OSX but not showing in Win10, I’m not sure if it’s completely healthy or not or if there is an issue in Windows. My main OSX drive is showing correctly in Windows though without any issues, it’s just this external drive giving me issues and only in Windows.
Any suggestions I could try?
Thanks
Was able to fix it but had to get another drive to transfer my files to. The drive somehow ended up having it’s partition table turned into APM somehow which wasn’t readable in windows but was in osx, so had to reformat it to MBR.
I mounted my OSX Journaled hard disk onto a Windows machine, Windows didn’t recognize my disk (because of HFS format). I wasn’t aware of HFS Explorer or any other programs that could access HFS drives on Windows. Naturally, I launched Disk Management and it prompted something (like use it as a dynamic disk or basic) to which I clicked yes (like an idiot).
After much searching here and there I have realized what just happened. And I followed the steps here. Just like another user posted, when at step 5 and I hit Analyze, it gives me
Bad MAC partition, invalid block0 signature
and then it gives me Quick Search instead of Quick Analyze.
I then hit Enter, it scans through and It keeps going for hours.
Did I do something wrong?
Thank you Perro. I sure hope you could help me out here.
HOW CAN I BUY YOU A DRINK.
Use the center to create big tiles, then move
them to the corners to combine them with the ones already there.
Yes, it’s true but unless you’re using epoxy-based grout, the grout has to be sealed.
A myriad of alternatives are available to match any
room design.
Because of a mistake, I’m trying to recreate my erase partition table on a 4TB disk.
I did the testdisk scan which gave me this:
TestDisk 7.0, Data Recovery Utility, April 2015
Christophe GRENIER
http://www.cgsecurity.org
Disk /dev/rdisk1 – 4000 GB / 3726 GiB – 7814037168 sectors
Partition Start End Size in sectors
P Mac HFS 409640 977167455 976757816
P Mac HFS 977429600 1172937415 195507816
P Mac HFS 1173199560 1564019871 390820312
P Mac HFS 1564282016 2150414831 586132816
P Mac HFS 2150676976 2736809791 586132816
P Mac HFS 2737071936 2932579751 195507816
P Mac HFS 2932841896 4885966895 1953125000
D Mac HFS 4886229040 7404276159 2518047120
D MS Data 7279506201 7413003032 133496832
D MS Data 7404760075 7404766248 6174
D MS Data 7404766248 7404772421 6174 [Boot]
D MS Data 7404827875 7404848613 20739 [NO NAME]
D MS Data 7406124163 7406130336 6174
D MS Data 7406130336 7406136509 6174
D MS Data 7406763385 7407480184 716800
D MS Data 7407480184 7408196983 716800
D MS Data 7408270865 7410311056 2040192 [NO NAME]
D MS Data 7410357625 7412397816 2040192 [NO NAME]
D MS Data 7413003032 7546499863 133496832
D MS Data 7464333896 7598524777 134190882
D MS Data 7590503992 7590506871 2880 [EFISECTOR]
D MS Data 7598524777 7732715658 134190882
P Mac HFS 7748460228 7752026043 3565816
P Mac HFS 7768041224 7768065719 24496
P Mac HFS 7782512556 7785540579 3028024
P Mac HFS 7785540670 7788568693 3028024
Now when I try to create the table I get the error message: “the map is not big enough”
pdisk: No valid block 1 on ‘/dev/rdisk1’
Edit /dev/rdisk1 –
Command (? for help): i
A physical block is 512 bytes:
A logical block is 512 bytes:
size of ‘device’ is 4294967295 blocks (512 byte blocks):
new size of ‘device’ is 4294967295 blocks (512 byte blocks)
the map is not big enough
Command (? for help): c
First block: 409640
Length in blocks: 976757816
Name of partition: sys10
the map is not big enough
And if i do a print command I get:
Command (? for help): p
Partition map (with 512 byte blocks) on ‘/dev/rdisk1’
#: type name length base ( size )
1: Apple_Free Extra 4294967294 @ 1 ( 2.0T)
Device block size=512, Number of Blocks=4294967295 (2.0T)
DeviceType=0x0, DeviceId=0x0
So it sees half the disk!
How can I create the table with that problem?
Thanks for any help
Luc
Luc, I had the same problem. Were you able to resolve?
If you no longer see your familiar volumes in Finder, and newly existing ones appear to be empty or cleared, you might have lost your partitions. While this may lead to the complete data erasure, if you act fast Disk Drill tool may be able to help you recover lost partitions on your Mac. You can find it here: http://download.cnet.com/Disk-Drill/3000-2094_4-75984417.html
hi
i borrow my sister laptop md313 and want to install windows 10 ,accidentally made a volume in disk management in windows,then mac doenst boot..just windows can use……….pleeeeeeez tell me what should i do with this program or anything else thanks…….
man,i’m completely fucked up,please help me
i have same problem Agha said to you……
I’m trying to expand my boot camp windows partition, but I converted my disk to a dynamic disk accidentally. Now my entire disk in my iMac is a dynamic disk, and I’m not able to boot to OS X. How can I revert the process without the loss of data? I’m able to boot Windows 7 but I don’t know how to resolve this problem without losing all my data in mac partition. I tried use TestDisk but I don’t understand how to use it especially when choosing which drive/partition and partition type. I’m not sure of it.
You are an absolute GENIUS!
Saved my life after I stupidly initialised an external HFS+ drive in Windows. Worst of all it’s not even mine. I was given it to partition 50:50 for use with OS X and Windows.
Now need to find out how to delete the fat32 partition (not detected in Windows for some reason) and make the drive whole again. I won’t be trying again that’s for sure. The owner can buy another drive for Windows use.
you save my semester. Thanks
Thanks for the good writeup. It in truth was a enjoyment account it. Glance complicated to more delivered agreeable from you! However, how can we communicate?
Hi,
I wanted to buy you drink, but it seems that it will be little bit delayed.
I am using OSX (10.6 and 10.9), I had a 3To Barracuda on USB Dock with EFI and 3 HFS+ partitions.
While building a NAS (QNAP TS-431 with 4.1.4 ) to save all this data, I had USB bad connexions and my 3To drive became a 800Gb without all 3 partitions 🙁
/dev/disk1 – 801 GB / 746 GiB – 1565565872 sectors
How can I correct this ? I’ve used testdisk, pdisk and gpt as describe below, and I am still in bad situation, because of this bad capacity, isn’t it ?
1) with testdisk : I succeed to get the normal partition information’s
———————– testdisk
Interface Advanced
hdr_size=92
hdr_lba_self=1
hdr_lba_alt=5860533167 (expected 1565565871)
hdr_lba_start=34
hdr_lba_end=5860533134
hdr_lba_table=2
hdr_entries=128
hdr_entsz=128
check_part_gpt failed for partition
3 P Mac HFS 1954182840 4884449423 2930266584 [sav films]
check_part_gpt failed for partition
4 P Mac HFS 4884711568 5860270983 975559416 [timemachine]
1 P EFI System 40 409639 409600 [EFI System Partition]
2 P Mac HFS 409640 1953920695 1953511056 [sav Photos]
HFS+ blocksize=4096, 1000 GB / 931 GiB
3 P Mac HFS 1954182840 4884449423 2930266584 [sav films]
4 P Mac HFS 4884711568 5860270983 975559416 [timemachine]
TestDisk exited normally.
———————–
After I’ve tryed to became a man … unfortunatly I have pratique little bit more.
With disk : I’ve rewrite the EFI partition, which became HFS+, I guess, and testdisk couldn’t find that the disk had a previous EFI.
With gpt : I’ve install EFI partition again, now the testdisk accept the disk as a EFI/GPT but can’t see anymore the 3 old partitions. This seems a normal effect of the rewriting EFI partition isn’t it ?
With pdisk : insert partition table information with testdisk information but :
I’ve got 2 messages : “pdisk: Can’t read block 2 from partition 2 / pdisk: Can’t read block 2 from partition 3”
and this one which underlines the bad disk capacity, isn’t it ? : “requested base and length is not within an existing free partition”
The result is a bad partition table, and a 800Gb disk to erase 🙂 when trying to mount it.
————————————-
Partition map (with 512 byte blocks) on ‘/dev/rdisk1’
#: type name length base ( size )
1: Apple_partition_map Apple 63 @ 1
2: Apple_Free Extra 589744208 @ 64 (281.2G)
3: Apple_HFS timemachine 975559416 @ 589744272 (465.2G)
4: Apple_Free Extra 388879152 @ 1565303688 (185.4G)
5: Apple_HFS sav 2930266584 @ 1954182840 ( 1.4T)
6: Apple_Free Extra 976083744 @ 589482128 (465.4G)
Device block size=512, Number of Blocks=1565565872 (746.5G)
DeviceType=0x0, DeviceId=0x0
——————————————-
HI,
I am having a “the map is not big enough ” problem.
and here is the process.
Wings-MacBook-Pro:~ mcchiu$ sudo pdisk /dev/rdisk2
Password:
pdisk: No valid block 1 on ‘/dev/rdisk2’
Edit /dev/rdisk2 –
Command (? for help): c
No partition map exists
Command (? for help): i
pdisk: can’t open file ‘/dev/rdisk2’ for writing (Resource busy)
Command (? for help): c
No partition map exists
Command (? for help): i
A physical block is 512 bytes:
A logical block is 512 bytes:
size of ‘device’ is 3907029168 blocks (512 byte blocks):
new size of ‘device’ is 3907029168 blocks (512 byte blocks)
the map is not big enough
Command (? for help):
AS i have read the comment above , someone say that the block should be 4096 bytes, may i know is it relevant ?
Hi I have a similar issue to the one describe above except it is a SD card (which also has most of my life on it) and it has a single partition in exFAT. Can I use the same process to repair the card ?
Do I need some extra steps to do this ?
Thanks a lot,
this is the best HFS+ repair in the internet. Worked perfect.
Many years of Pictures came back to life.
Thanks again
thank you perro.
its works
Thank you. Thank you. Thank you.
Worked like a charm.
Thanks perru! it worked de pm 😉
Hello guys! I’ve just fixed my external drive. So I’ll show you how to solve “the map is not big enough ” problem. The problem is on that step when you’re using ANALYSE in TestDisk. BEFORE starting analysing your disk you should change disk geometry. Choose GEOMETRY and change the sector size according to this table:
Volume Size_____________Default Block Size
<=256 MB_______________512 bytes
256 MB <= 512 MB________1024 bytes (1K)
512 MB 1 GB__________________4096 bytes (4K)
When block size is changed correctly hit OK and only then run ANALYSE and you’ll get totally different “Start End Size in sectors” numbers. Then using THESE numbers in pdisk you won’t get “the map is not big enough” problem and you’ll fix your drive easily! Good luck!
I get a lot of emails asking about the block size, thanks for sharing the table!
I changed the block size and still shows the map not big enough…What can be the issue?
Do you need to save the change block size before closing tesdisk and go to pdisk?
My analysis in tesdisk is good with 8192 but pdisk is still using 512;
THANK YOU SO, SO MUCH! THIS REUNITED ME WITH ALL MY STUFF ON MY ONE AND ONLY EXTERNAL HARD DRIVE, DURING A WEEK WHEN I REALLY NEEDED TO ACCESS SOME IMPORTANT FILES ON IT FOR A PROJECT TO WORK ON! HERE’S A DONATION FOR ALL YOUR HELP! MANY PEOPLE OUT THERE ARE STRUGGLING WITH A SIMILAR PROBLEM TO WHAT I HAD…THIS SOLUTION SHOULD BE BETTER PUBLISHED!
I’m glad it worked for you 🙂
Thanks Perro!
Trying to bring back 4Tb portable Seagate drive. Until disk everything worked.
For physical and logical block I try to put 512, 4096 or 8192, but
“size of ‘device’ is 0 blocks” whatever I try.
Can you advice?
testdisk is telling
Block size 8192
Sector size 4096 if i am able to read it right
Thanks to TestDisk, that I found thanks to you, I recovered my partition. Thank you!
How to repair HFS+ partition? * Error 53 Iphone Fix
[ASK] apple - How to repair HFS+ partition? | Some Piece of Information
I came to this site like many of the others here trying to find a way to retrieve my precious documents from my external hard drive. The problem started when I didn’t properly eject my hard drive.
It is a 1TB drive divided into 3 parts. Currently I can read and write to only the FAT partition. The other 2 HFS partitions only show up as Untitled and can’t be read.
//////////////
TestDisk 7.0, Data Recovery Utility, April 2015
Christophe GRENIER
http://www.cgsecurity.org
Disk /dev/rdisk1 – 1000 GB / 931 GiB – 1953525168 sectors (RO)
Current partition structure:
Partition Start End Size in sectors
No HFS or HFS+ structure
1 P HFS 63 195574710 195574648
1 P HFS 63 195574710 195574648
>
Warning: Bad ending sector (CHS and LBA don’t match)
2 P HFS 195574743 1758737054 1563162312
Warning: Bad starting sector (CHS and LBA don’t match)
check_FAT: Unusual media descriptor (0xf0!=0xf8)
Warning: number of heads/cylinder mismatches 255 (FAT) != 1 (HD)
Warning: number of sectors per track mismatches 32 (FAT) != 1 (HD)
3 P FAT32 1758737106 1953525167 194788062 [ALHASIB FAT]
Warning: Bad starting sector (CHS and LBA don’t match)
>No partition is bootable
*=Primary bootable P=Primary L=Logical E=Extended D=Deleted
>[Quick Search] [ Backup ]
Try to locate partition
//////////////
Any help would be wonderful.
seems like that information is enough to try to put it in pdisk. is that the results of the quick search? the second and third partition look fine to me, but the first one seems to have no size. can you post a link to a screenshot of the quick search
Hey,
thank you so far for your tutorial. I accidentely formated my HFS external hard drive with exfat4. now i try to get the data back. my problem is, the it needs a lot of time to scan the harddrive.
Analyse Cylinder 700/230000
It will probably need 24h to scan (2TB). is this normal? or am i doing something wrong?
Thank you,
Alex
Did you tried the fast scan first? Did it yield any results?
Hey,
I did a quick search but it Listed two HFS Partitions with nearly identical Start stop sectors as “cant be recovered” with an error: the hard disk is too small.
Might one of those be my partition?
Hi there,
I accidentally erased my external HD with disk utilty. It was formatted as OS X Extended (Journaled) and I erased it using the same format.
When I run the quick search only one HFS partition shows up, which I assume is the new empty one. Should I run the deep search?
Thanks
hmm, I think in that scenario the damage is greater than just recovering the partition, you’ll probably going to need to get a tool that read the bits of the drive and recover files, most cases you can recover files, but not the folder structure you had
Hi perrohunter
Thanks a lot for your reply. Using a data recovery software I recovered everything but without file names. But I have 2TB of files, which is a nightmare to reorder. After doing a deep search with testdisk a few hundred HFS+ deleted partitions show up. Do you think something could be done with those partitions to recover the folder structure?
Thanks and regards
I highly doubt it, the thing with HFS+ (Hierarchical File System) is that all the folder structure (which was introduced with the + on HFS) is stored in a single place, and upon formating that information is wiped out and the rest of the data on the drive is ignored,, that’s why it’s so fast to format an HFS+ volume yet easy to recover data but without structure.
Hi Perro,
I was transferring files from one external HD (WD passport) to another external HD (WD My Book Essential 2TB) when the power plug for the My Book Essential 2TB got pulled out. I couldn’t repair it using Disk Utility, and when I ran TestDisk, it once told me that “Write access for this media is not available.” And I tried unmounting it from Terminal. Anyway, I got into pdisk and made it to the next steps:
Command (? for help): c
No partition map exists
Command (? for help): i
pdisk: can’t open file ‘/dev/rdisk3’ for writing (Resource busy)
How do I go about this? Thanks! Your help will deinitely be appreciated!!!
Internet Explorer For Os X 10.8.5 | KInsurance
How To Backup Mac Os X 10.4.11 To External Drive | cambodiastar
Dear Perro Hunter,
I followed your and my HD is still messed up. Even more!
I explain my situation to you: my hd has three equal partitions. One of them doesn’t mount. Disk utility sees it but isn’t able to mount it and tells me to repair it. I don’t know how to recover the files before repairing.
I followed your steps here but unfortunately it didn’t work. I have more partitions but the troubled partition keeps unmounted. What am I doing wrong? I appreciate any help.
Kind regards.
Jose
Does anyone know why the message the map is not big enough remains even after trying all sector sizes? It looks it should be 4096 for a 2TB external but tried other sizes as well.
I could see from Data Rescue the full structure is there however it does not mount. Please any help would be appreciated. Thanks!
Hello Perro,
From the JMCD case (June 2016), what can you say about the iMovie file structure? Is there good chances to recover at least the movie files in one piece? (Please say yes… 🙂 Thanks!
What block size should I put for a 4TB drive?
Hey,
Thx for all this help.
I’m dealing with two 4TB hdd that are likely to have gpt damaged due to unplugging hazard.
I can also access data but only via diskdrill pro. Disk utilities sees a blank partition on each drive.
I would like to rebuild gpt without having to do a very long backup and formating process (each hdd is nearly full)
Looks like blocksize is 8192 , the testdisk sees the partition as one hfs+
I changed the geometry to 8192.
But in pdisk it is still recognized as 512, so I have the same mapping size error.
What did I miss?
Hello Polo,
Most of the times this issue is due to disk manufacturers using different block sizes to increase storage capacity in their devices.
Usually the way to figure out the right block size is taking the number of blocks from testdisk and doing some math around number of blocks and expected device size to figure out the right block size. What’s your disk vendor and model?
Hery perro,
It’s a wd red nasware 4to
Dear Experts,
I’ve got a 1TB WD Elements external hard disk that was formatted into a single partition MacOS X Journaled and encrypted, it worked well since I connected it to my new MacBook Pro 2016 15” suddenly the disk stopped working. Now when I run First Aid in Recovery mode this is what I get:
“First Aid found corruption that needs to be repaired. To repair the startup volume, run First Aid from Recovery.”
Here under the details:DiskUtility.png
Checking prerequisites
Checking the partition list
Checking the partition map size
Checking for an EFI system partition
Checking the EFI system partition’s size
Checking the EFI system partition’s file system
Checking the EFI system partition’s folder content
Checking all HFS data partition loader spaces
Checking booter partitions
Checking booter partition disk2s3
Verifying file system.
Checking Journaled HFS Plus volume.
Checking extents overflow file.
Checking catalog file.
Checking multi-linked files.
Checking catalog hierarchy.
Checking extended attributes file.
Checking volume bitmap.
Checking volume information.
The volume Boot OS X appears to be OK.
File system check exit code is 0.
Checking Core Storage Physical Volume partitions
Problems were found with the partition map which might prevent booting
Operation successful.
My partition is gone, no volume, nothing…
Do you have any idea how I can get back my data?
Verifying and repairing partition map for “WD Elements 25A2 Media
”Checking prerequisitesChecking the partition list
Adjusting partition map to fit whole disk as required
Checking for an EFI system partition
Checking the EFI system partition’s size
Checking the EFI system partition’s file system
Checking the EFI system partition’s folder content
Checking all HFS data partition loader spaces
Checking booter partitionsChecking booter partition disk1s3
Repairing file system.
Checking Journaled HFS Plus volume.
Checking extents overflow file.
Checking catalog file.
Checking multi-linked files.
Checking catalog hierarchy.
Checking extended attributes file.
Checking volume bitmap.Checking volume information.
The volume Boot OS X appears to be OK.
File system check exit code is 0.
Updating boot support partitions for the volume as required.
Reviewing boot support loaders
Checking Core Storage Physical Volume partitions
Repairing storage system
Checking volumedisk1s2:
Scan for Volume Headers
Invalid Volume Header @ 0: incorrect block type
Invalid Volume Header @ 999826611712: unsupported format
disk1s2 did not complete formatting as a CoreStorage volume
Storage system check exit code is 1.
Problems were encountered during repair of the partition map
Error: This disk needs to be repaired. Click Repair Disk.
By the way repair disk never worked. Could you please help?
Thanks!!!!
When everything had seems to end by the most awful way… your MAGICAL POST gave peace to my heart.
Thanks a lot for your help!!!!!
You deserve the best donation I ever made in my entire life
So this has actually happened to me twice in the last two months, on two different drives and I feel like I have gone over and over and tried everything in this thread and still no luck. The biggest question that I have that doesn’t seem to be getting answered is what could be an ideal default block size for a volume size that is 4TB. I’ve seen the question alluded to but no general answer.
Also, and this is just me thinking out loud, but why has TestDisk been around for so long and STILL doesn’t support the HFS+ stuff? Like, what amount do we need to pay to get the creator to update the program and get that working?
The block size for 4TB is really hard to figure out since it’s based on vendor/device.
Regarding HFS+ support I wonder the same, HFS is a really old file system but maybe it doesn’t justify the time and effort for testdisk to add support
Internet Explorer For Os X 10.8.5 | cn
Hi Perrohunter,
Would you mind if we use your article on our website – http://macsecurity.net? Of course, with the link reference to you.
Thanks so Much Perrohunter. your method helped to me get all my data back from a cloned HFS+ HDD. It even mounted the hidden Recovery Drive partition.
I need so me advice though. I have 2 fat32 formatted hdd’s with bad partition maps. when I follow your steps I get: ‘requested base and length is not within an existing free partition’. I go ahead any way and proceed to write the map, I get the following:
pdisk: Unable to write block zero (Invalid argument)
pdisk: Unable to write block 1 (Invalid argument)
pdisk: Unable to write block 2 (Invalid argument)
both drives have 4096 logical sectors. should I change them to 512 in Testdisk geometry menu? thanks for the help so far.
Hi, [PERR0_HUNTER]!
I have seen several people asking the same question as I do, but could not find solution. The TestDisk runs quick search very slow. I presume it will run for several days with its current speed.
Could you please tell me if there is a way to make quick search quicker? it is testdisk 7.0 I am using.
Thanks,
Konstantin
Fabulous! Your routine worked for me on my recalcitrant external USB drive running Mac OSX 10.11.6 and testdisk-7.1-WIP. I had backed up my problematic drive beforehand using Disk Drill but this procedure is a great help.
A Huge Thanks to you,
Richard
Mac分区表恢复 – BigYuki Sharing
I have noticed you don’t monetize your site, don’t waste your traffic, you can earn extra bucks every month because you’ve got hi quality content.
If you want to know how to make extra bucks, search for: Mrdalekjd methods for $$$
You are a GOD! Thank you, worked like a charm.
I accidentally formatted an HFS drive as NTFS. I’m first recovering all of the data (which seems intact) to another drive, but is there a way to “reverse” the format and revert the drive to its HFS state?
Yes, recovering the partition table with this procedure should rever the damage, but just to be sure do keep recovering all the data you can before attempting this as you are already doing.
This procedure is harmless and does not affect data
The data is almost finished recovering, thanks. How do I know what to list for the sector sizes? Is that something that I need to figure out myself?
I’m concerned I’m not “expert” enough to do it and it’s best to leave the hard drive the way that it is, and let a professional deal with it.
I see you don’t monetize your site, don’t waste your traffic, you can earn extra
bucks every month because you’ve got high quality content.
If you want to know how to make extra $$$, search for:
Mertiso’s tips best adsense alternative
Hi, short question. Is this solution applicable hfs+ partition that I accidentally reformatted to another empty hfs+ partition using disk utility? all the files should be there just not the partition table…
regards
Lukas
I’m having a macbook pro 15 retina early 2013, in which I’m trying to erase my ssd because high sierra osmy has been corrupted showing folder question mark. I can only access internet recovery. My ssd is detecting in diskutility as UNINITIALIZED. I thought that my ssd has failed, but when I erase it, it’s says waiting for disks to reappear at 50%. I tried pdisk command in terminal where I can initialize, write partitions to my ssd but that doesn’t show up in diskutil list. I did this because to check whether my ssd is functioning properly or not.
I asked help from several forums they said to mount my ssd externally to a Linux through livecd and use gparted. the same problem occurs cant format using ext4 or fat32 or even hfs+. it detects as a unrecognized label and shows my file system as unallocated.
Im slowly trying to understand the fact that my ssd is failing but my question is how can it detect or how can it initialize and write partitions through pdisk and I checked badblocks and no badblocks occurred in my process. Also when using dd in terminal it stated some records are in and some records are out like that.
I tried zerodisk erase which did till 99%and after that stated error 69759 erasing failed and underlying error 5 input/output error
I literally did everything possible I can. Kindly help me
I just want to format the ssd and install a osx.
Just checking in to say that this guide worked perfectly. Bootcamp hosed my partition table, I got the “prohibited sign” when booting up. I started in target mode with a thunderbolt cable to attach the drive to another mac, got the info I needed from testdisk, and as soon as I wrote the new partition table it was recognized. I got the “bad size” error when writing the first partition at block 40, but it still boots just fine. Thanks!!
Thanks for recovering a RAID setup that appeared hosed!
TestDisk was useful but didn’t have the option to repair the partition table, your pdisk instructions were the missing link and have helped greatly.
Hope you enjoy the beers!
Your website thrusts my CPU to 300% coz of CoinHive. How can I trust your instructions after this highjacking attempt?
it looks like it, I’m looking into it
I often visit your website and have noticed that you don’t update
it often. More frequent updates will give your site higher authority
& rank in google. I know that writing posts takes a lot of time, but you can always help yourself
with miftolo’s tools which will shorten the time of creating an article to
a few seconds.
thank you so much for offering a glimmer of hope while I am attempting to recover data from my internal hd that seems to have been corrupted or lost the partition map and won’t boot up anymore, i dunno. It shows up in my disk utility but is grayed out and cannot be verified or repaired. I installed the os on an external drive and booted up from there. I’m trying to save the data that is on the internal drive and I followed your directions to the near end. I quit once it asked something like “Writing the map destroys what was there before. Is that okay?” because i’m not sure which data will be destroyed. Does this mean that all data on the drive will be destroyed? or just the data pertaining to the plots of the map? or just the data within the partition range?
Also, i’m wondering why there was only one partition detected. I never partitioned the drive but it was the drive i used to run my OS. So shouldn’t there be two partition areas? one for the OS and the other for the rest of the data?
pdisk: No valid block 1 on ‘/dev/rdisk0’
Edit /dev/rdisk0 –
Command (? for help): c
No partition map exists
Command (? for help): i
A physical block is 512 bytes:
A logical block is 512 bytes:
size of ‘device’ is 1954210120 blocks (512 byte blocks):
new size of ‘device’ is 1954210120 blocks (512 byte blocks)
Command (? for help): c
First block: 40
Length in blocks: 409600
Name of partition: one
requested base and length is not within an existing free partition
Command (? for help): w
Writing the map destroys what was there before. Is that okay? [n/y]: n
Thank you so much!
I accidentally had overwritten the GUID Partition Table (on windows) and stopped seeing my HFS+ partition. Test disk was able to recover it!
I didn’t have to run pdisk. After analysing the disc, testdisk gave me the option to write back the partition, just selected it and voila!
Best regards!
You sir are a Hero. Ages trawling the net and loads of useless recovery software – should have come straight here!
Hello Perro Hunter,
I have a drive that stopped mounting and tried, Data Rescue, Disk drill and PhotoRec to unsuccessfully recover files.
It’s a 3TB one but OSX can see only a drive of 801.57GB and cannot mount.
I tried your way a couple of times and now my hard drive has three partitions:
Apple_partition_map 32kB
i 104.84GB
( 262.65GB
Still, cannot mount.
I am sure my files are still in there because the drive stopped mounting out of the blue and I ever did a format to delete it.
Data Rescue can see the tree correctly but cannot recover.
Is there a way to revive the original single partition and have access to those folders and files?
Many thanks.
Good day
I just checked out your website perrohunter.com and wanted to find out if you need help for SEO Link Building ?
If you aren’t using SEO Software then you will know the amount of work load involved in creating accounts, confirming emails and submitting your contents to thousands of websites.
With THIS SOFTWARE the link submission process will be the easiest task and completely automated, you will be able to build unlimited number of links and increase traffic to your websites which will lead to a higher number of customers and much more sales for you.
IF YOU ARE INTERESTED, We offer you 7 days free trial
CONTACT US HERE ==> dindinaa421@gmail.com
Regards,
Best Seo Software
QuickBooks Error H202 is an error of multiuser operational mode on QuickBooks. There are number of indications that shows the presence of QuickBooks Error H202.
Keep a check to your incorrect hosting configuration. There might be your system’s firewall which is blocking all of the in & out communication.
Well done man, you saved me
I pay a visit each day a few blogs and websites to read articles or reviews, however this webpage offers feature based writing.|
Ive been trying to follow this post all day, think i have stuffed up my drives.
I have two drives, one Toshiba DT01ACA300 3.0TB desk drive and a WD WD30EZRX 3.0TB drive, that stopped mounting on my Mac after using a crappy top loading simple com drive adaptor. Now using test disk it originally showed the ‘P HFS’ Partition, (see pic)
https://ibb.co/Yb5n1Bm
Now after following the above in Terminal, i was changing the block sizes from 512 to 4096 and wrote to the drive. Now the drive doesnt even show the ‘P HFS’ Partition in testdisk anymore.
Is there a way of bringing the partition back? The errors i get in Terminal now when i try the above is:
pdisk: Can’t read block 2 from partition 2
pdisk: Can’t read block 2 from partition 3
ARGH! Any ideas?
Hey Perro Hunter,
Thanks for the great article, I was wondering would there be an email adress I could contact you on?
Thanks again man,
Dave
Thanks you very much for this post PerroHunter,you are a hero without cape !! I have a simple question: On step 8: My SATA drive was restored from and EMPTY drive( as HHD upgrade gone wrong) has been now formatted as Extended Journaled, with the installation of the MAC Os High Sierra which now shows 2 new partitions ( Recovery HHD and NameHHD).
I did a DeepSearch of the current drive as it is, and after waiting patiently ,I now have a LONG list of information with Partitions info , size, etc. ( something like “Juan May 31, 2014 at 4:31 pm”
What should be my next step?
Thanks again for your contribution !!
Last night, i have not sleep that much because my 4tb drive is not readable. The partition is not showing.
Then testdisk came today. Viola, i jus rewrite the partition info and everything is back the way it used to be.
I can now access all my partition and files
2012 MacMini HDD died while installing Win 10 Tech Preview - PhotoLens
How to restore a deleted HFS+ partition table? - PhotoLens
How to repair HFS+ partition? - PhotoLens
You are my HERO !!!
I accidentally deleted the partition full of my kid’s photos and now they’re back. Thank you very much!!!
Do you still monitor this site?
Hello There. I found your blog using Yahoo. This is a really well written article. I’ll be sure to bookmark it and come back to read more of your useful info. Thanks for the post.
I owe a debt of gratitude to the website owner for allowing me to repost this magnificent work.
https://macapps-download.com/diskwarrior/
Hi Perrohunter,
Thanks for all your outlined steps. I have the similar problem to many others, external hardrive that I have incorrectly removed and now no longer recognised.
I have followed steps 1-6. However on step 6 once analysing it does not present me with any partitions. Just a blank screen with – Bad MAC partition, invalid block0 signature read_part_mac: bad DPME signature (this is after hitting quick search)
Sorry, do you have any suggestions ?
As someone who struggles with mental health, I appreciate the support and empathy displayed in your blog It means a lot to know I’m not alone